- The paper presents a novel model that integrates CNNs for character-level feature extraction, BLSTMs for contextual modeling, and a CRF for joint label decoding.
- It achieves state-of-the-art results with 97.55% accuracy for POS tagging and a 91.21% F1 score for NER, validating its effectiveness.
- The architecture eliminates manual feature engineering by seamlessly integrating pre-trained word embeddings with automatically learned character representations.
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
This paper introduces a novel neural network architecture for sequence labeling that leverages both word- and character-level representations without task-specific feature engineering or data pre-processing. The model combines bi-directional LSTMs (BLSTMs), CNNs, and CRF layers, achieving state-of-the-art results on POS tagging and NER tasks.
Model Architecture
The architecture consists of several key components. First, a CNN extracts character-level information from words, encoding morphological features. The character-level representation is then concatenated with pre-trained word embeddings. This combined representation is fed into a BLSTM to model contextual information. Finally, a CRF layer jointly decodes the optimal label sequence for the entire sentence.
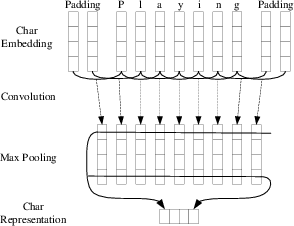
Figure 1: The convolution neural network extracts character-level representations of words, with a dropout layer applied before character embeddings are input to the CNN.
The CNN component is used to capture morphological information at the character level (Figure 1). The character embeddings are passed through a dropout layer before being fed into the CNN.
LSTM units, as a variant of RNNs, are designed to mitigate gradient vanishing problems (Figure 2).
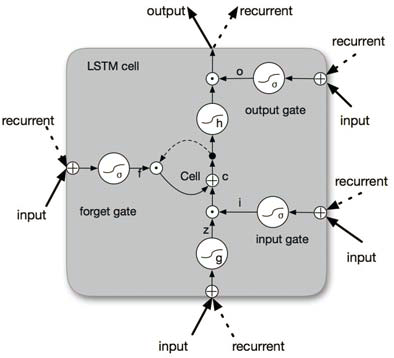
Figure 2: A schematic of an LSTM unit.
The LSTM units include multiplicative gates that control the flow of information, facilitating the learning of long-range dependencies. The BLSTM processes the input sequence in both forward and backward directions, capturing past and future contexts. This is particularly useful for sequence labeling tasks where context is crucial.

Figure 3: The main architecture of the neural network combines CNNs for character-level representation, BLSTMs for context modeling, and a CRF layer for joint decoding.
The complete architecture of the BLSTM-CNNs-CRF model is shown in Figure 3. Dropout layers are applied to the input and output vectors of the BLSTM to improve generalization.
Implementation Details
The model is implemented using Theano, and training is performed on a GPU. Key implementation details include:
- Word Embeddings: Pre-trained GloVe embeddings are used, but the paper also explores Senna and Word2Vec embeddings.
- Character Embeddings: Character embeddings are initialized randomly.
- Optimization: Mini-batch SGD with momentum and gradient clipping is used.
- Regularization: Dropout is applied to character embeddings and BLSTM inputs/outputs.
- Early Stopping: Validation set performance is used for early stopping.
The authors used Stanford's GloVe 100-dimensional embeddings, and also ran experiments using Senna 50-dimensional embeddings and Google's Word2Vec 300-dimensional embeddings. The best parameters were found at around 50 epochs using early stopping. The initial learning rate was set to 0.01 for POS tagging and 0.015 for NER.
Experimental Results
The model is evaluated on POS tagging using the Penn Treebank WSJ corpus and NER using the CoNLL 2003 corpus. The results demonstrate state-of-the-art performance, achieving 97.55\% accuracy for POS tagging and 91.21\% F1 score for NER. Ablation studies show that each component of the architecture (CNN, BLSTM, CRF) contributes to the overall performance. Using dropout significantly improved the performance of the model. The combination of BLSTM with CNNs to model character-level information significantly outperformed the BLSTM model.
The CRF layer improves performance by jointly decoding labels, capturing dependencies between them. The model's performance is also analyzed with respect to out-of-vocabulary (OOV) words, showing that the CRF component is particularly effective in handling OOV words.
Comparison with Previous Work
The proposed model outperforms previous state-of-the-art systems on both POS tagging and NER tasks. Compared to other neural network models, the key advantages are the end-to-end nature (no feature engineering) and the use of a CRF layer for joint label decoding.
Conclusion
This paper presents an effective and efficient neural network architecture for sequence labeling. The end-to-end nature of the model makes it easily adaptable to various tasks and domains. Future research directions include exploring multi-task learning and applying the model to other domains like social media.