- The paper introduces a hybrid model combining word embeddings and tf-idf to effectively capture semantic similarity in very short texts.
- The proposed method uses an importance factor approach that weights words by their idf values, addressing limitations of traditional overlap-based techniques.
- Experimental results on Wikipedia text fragments demonstrate enhanced performance in identifying semantically related texts by emphasizing rare, meaningful words.
Learning Semantic Similarity for Very Short Texts (1512.00765)
Abstract
The paper "Learning Semantic Similarity for Very Short Texts" (1512.00765) presents an investigation into improving semantic similarity measures for very short textual fragments, such as those typically found on social media platforms like Twitter or Facebook. Traditional text similarity measures, such as tf-idf cosine similarity, often perform inadequately on short texts due to limited word overlap. This paper explores combining word embeddings with naive and tf-idf techniques to generate a distributed sentence representation for better semantic matching between text fragments.
Introduction
The rapid proliferation of brief text communications on platforms such as Twitter and Facebook creates unique challenges for information retrieval algorithms designed to relate such text fragments. While traditional methods like tf-idf rely on term overlap, this is less effective for very short texts due to minimal word repetition. Recent advancements in distributed word embeddings, notably informed by Mikolov et al.'s work [Mikolov:2013wl], have demonstrated potential for discerning semantic relationships by capturing the essence of words beyond exact matches.
Conventional methods of combining word embeddings to derive sentence-level representations often fall back on simplistic techniques. Averaging or maximizing embeddings across a sentence, for instance, has proven insufficient for encapsulating full semantic content [Collobert:2011tk, Weston:2014tb]. More sophisticated attempts involve algorithms like paragraph2vec by Le and Mikolov (Francescone et al., 2014), which aim for amalgamating words into coherent sentence representations. However, paragraph2vec limitations arise due to its inability to process previously unseen paragraphs without additional training.
The development of word embeddings has prompted exploration into improving semantic similarity measures for short texts. The motivation behind this research is to bridge dense distributed representations with traditional tf-idf methodologies to construct an effective model for identifying semantically cognate short-text fragments.
Experimental Set-up and Analysis
To evaluate various semantic similarity techniques on short text fragments, a dataset was constructed from English Wikipedia. Pairs and non-pairs of text fragments were drawn from 10, 20, and 30-word sections of article paragraphs, designed to test different similarity measures on known similar and non-similar text instances.
Word vectors were trained using word2vec on a full Wikipedia dump, employing a skip-gram with negative sampling, and a context window set at five words. Then, comparisons were made using different aggregation strategies.
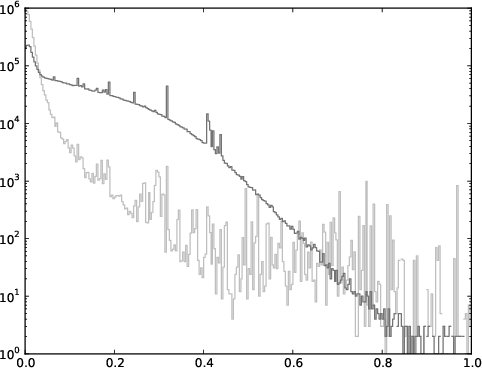
Figure 1: Histogram plot of the number of couples as a function of their cosine similarity using tf-idf, for both pairs (dark grey) and non-pairs (light grey).
From (Figure 1), the limitations of traditional tf-idf emerge, as the overlap of infrequent words in short texts often fails to achieve significant discriminative power between pairs and non-pairs. This led to the development of alternative techniques, including taking the mean and maximum of word embeddings.
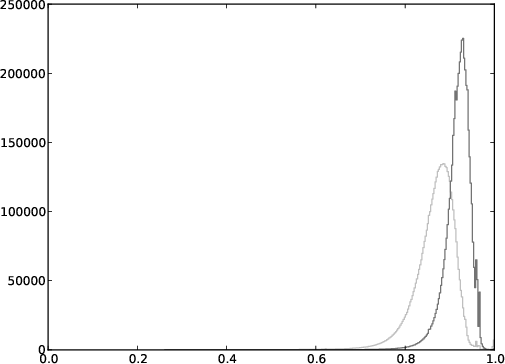
Figure 2: Histogram plot of the number of couples as a function of their cosine similarity using the mean of the word embeddings, for both pairs (dark grey) and non-pairs (light grey).
These traditional approaches did not entirely resolve the overlap issue seen in non-informative words, which maintained a degree of difficulty in distinguishing semantic similarity.
Importance Factor Approach
Evaluation of the word vector aggregation techniques focused on reducing the confounding overlap created by frequent, non-informative words. The authors introduced an appreciation of the Inverse Document Frequency (IDF) in the word vectors.
Figure 2: Comparison between mean embeddings and the importance factor approach, for both pairs (dark grey) and non-pairs (light grey).
An innovative weighting strategy was adopted whereby word vectors in a text were weighted by their idf values. The proposed importance factor approach effectively emphasized rare, informative words over frequent non-informative ones. This culminated in marked improvements in detecting semantically similar text fragments.
Figure 3: Plot of the importance factor magnitudes.
The importance factor magnitudes display a notable decreasing trend, lending credence to the assumption that words with low document frequency—and thus high importance—were more heavily weighted. This technique yielded significant performance gains.
Conclusion
The research detailed in this paper brings a significant advancement toward a unified methodology for semantically evaluating short text fragments by harmonizing word embedding and tf-idf data. Despite its promising findings, several limitations were acknowledged, including the necessity to transfer this approach to more general, non-fixed-length text tasks, and to adapt the technique to typologically varied texts such as social media posts. Future research will likely expand on these dimensions, exploring more sophisticated integration methods and cross-textual embedding comparisons.