- The paper's main contribution is the development of KBLAS, an open-source library that optimizes dense matrix-vector multiplication on NVIDIA GPUs using double-buffering and tunable parameters.
- It details advanced kernel implementations and novel interfaces for submatrix operations that enhance memory coalescence and integrate seamlessly with NVIDIA cuBLAS and MAGMA.
- Performance evaluations demonstrate up to 50% and 60% speedup on single- and multi-GPU systems, underscoring the library's portability and efficiency.
KBLAS: An Optimized Library for Dense Matrix-Vector Multiplication on GPU Accelerators
KBLAS is presented as an open-source library delivering optimized kernels for a subset of Level 2 BLAS functionalities on CUDA-enabled GPUs, emphasizing memory access optimization through double-buffering. This library achieves performance improvements on various GPU architectures without requiring code rewriting, while adhering to the standard BLAS API. A subset of KBLAS kernels has been integrated into NVIDIA's cuBLAS, starting with version 6.0.
Contributions of KBLAS
The work makes several key contributions:
- Improved performance of SYMV/HEMV and GEMV kernels on single GPUs across different generations via tunable performance parameters.
- New interfaces for GEMV and SYMV/HEMV kernels operating on submatrices, eliminating non-coalesced memory accesses.
- New GEMV and SYMV/HEMV kernels for shared-memory multi-GPU systems, abstracting hardware complexity and transparently managing memory.
- Release of all kernels into a single open-source library named KBLAS.
GPU Architecture and Programming Model
GPUs are presented as many-core architectures designed for high processing throughput, using the SIMT model where multiple threads execute the same instruction on different operands. A typical GPU architecture consists of Streaming Multiprocessors (SMs), each with multiple CUDA cores, a memory hierarchy including L1 cache/shared memory, register file, constant cache, L2 cache, and global DRAM (Figure 1).
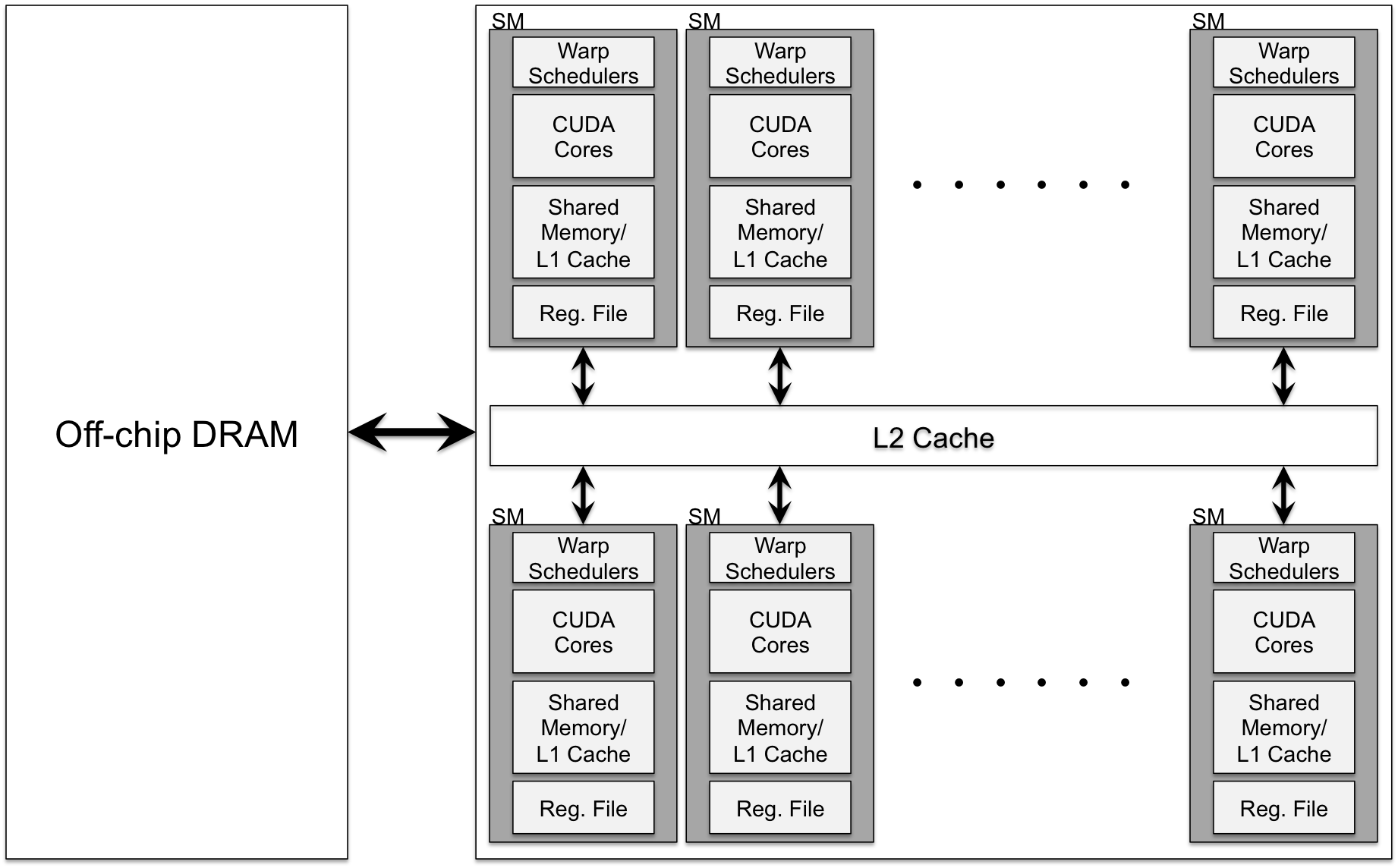
Figure 1: A modern GPU architecture.
The CUDA programming model is leveraged for KBLAS development, organizing CUDA kernels as a grid of thread blocks (TBs), where TBs are executed by one SM and threads within a TB can share data and synchronize. Performance considerations for memory-bound kernels include coalesced memory access, GPU occupancy, and data prefetching.
KBLAS Library Structure and Data Layout
KBLAS comprises CUDA source codes and C-based testing codes, with CUDA source codes divided into kernel templates (abstracted CUDA kernels using C++ templates) and kernel instances (instantiated precisions with specific tuning parameters). The library implements the BLAS operation y=αAx+βy with routines for GEMV, SYMV, and HEMV in single and multiple GPU configurations.
For single GPU routines, KBLAS supports the BLAS standard column major format with padded leading dimensions to preserve memory coalesced access (Figure 2).

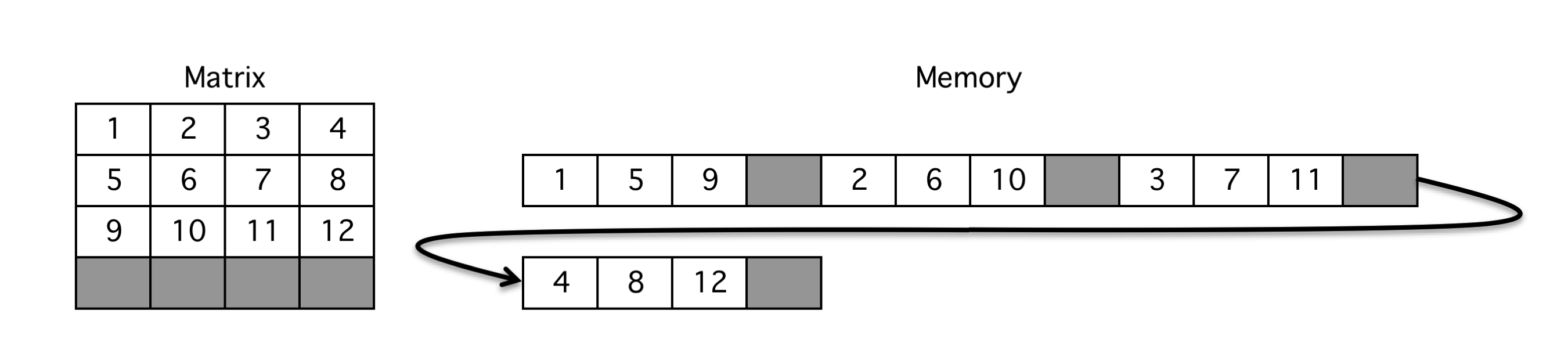
Figure 2: Column major layout for single GPU kernels.
For multi-GPU routines, matrices are distributed in a 1D cyclic manner by block columns (Figure 3).
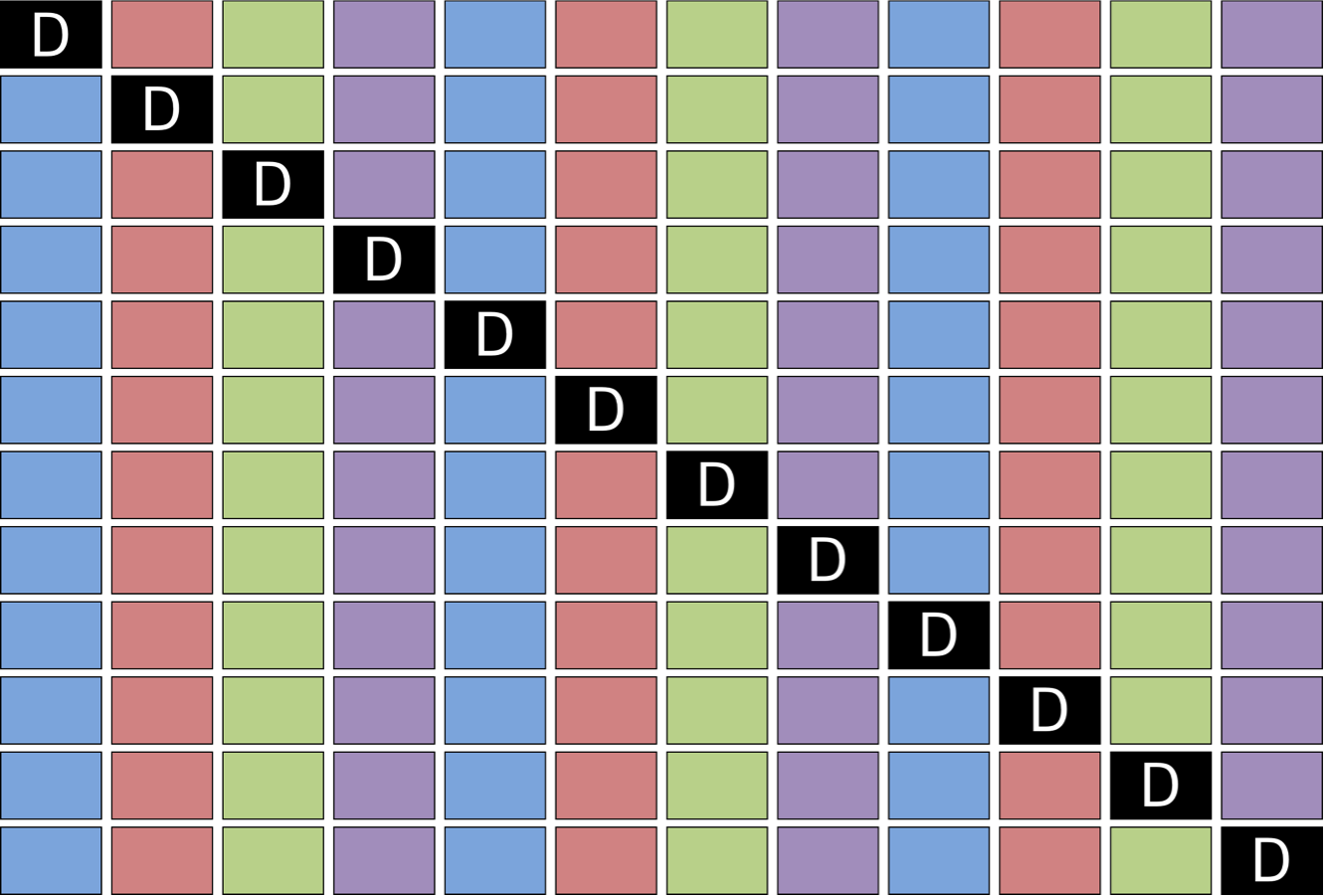
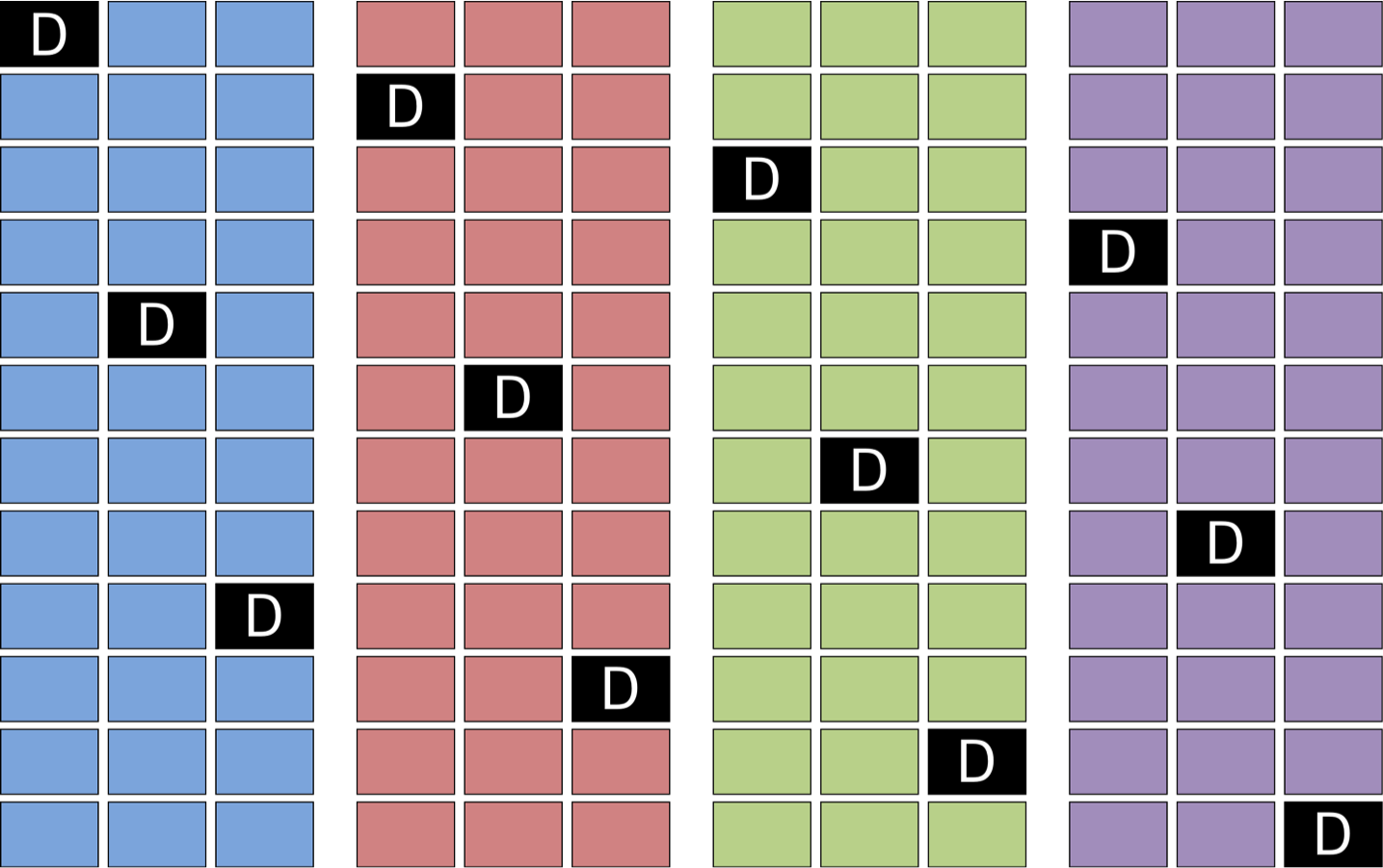
Figure 3: Matrix layout for multi-GPU kernels.
KBLAS kernels process input matrices in square blocks of size nb, a tuning parameter. The grid is organized as a 2D array of TBs with dimensions (Xˉ, Yˉ), where Yˉ is a tuning parameter and Xˉ is determined by the problem size. Each TB is a 2D array of threads of size (Pˉ, Qˉ), where Pˉ=nb and nb0 is a tuning parameter. TBs are designed to maximize memory throughput via double buffering (Figure 4).
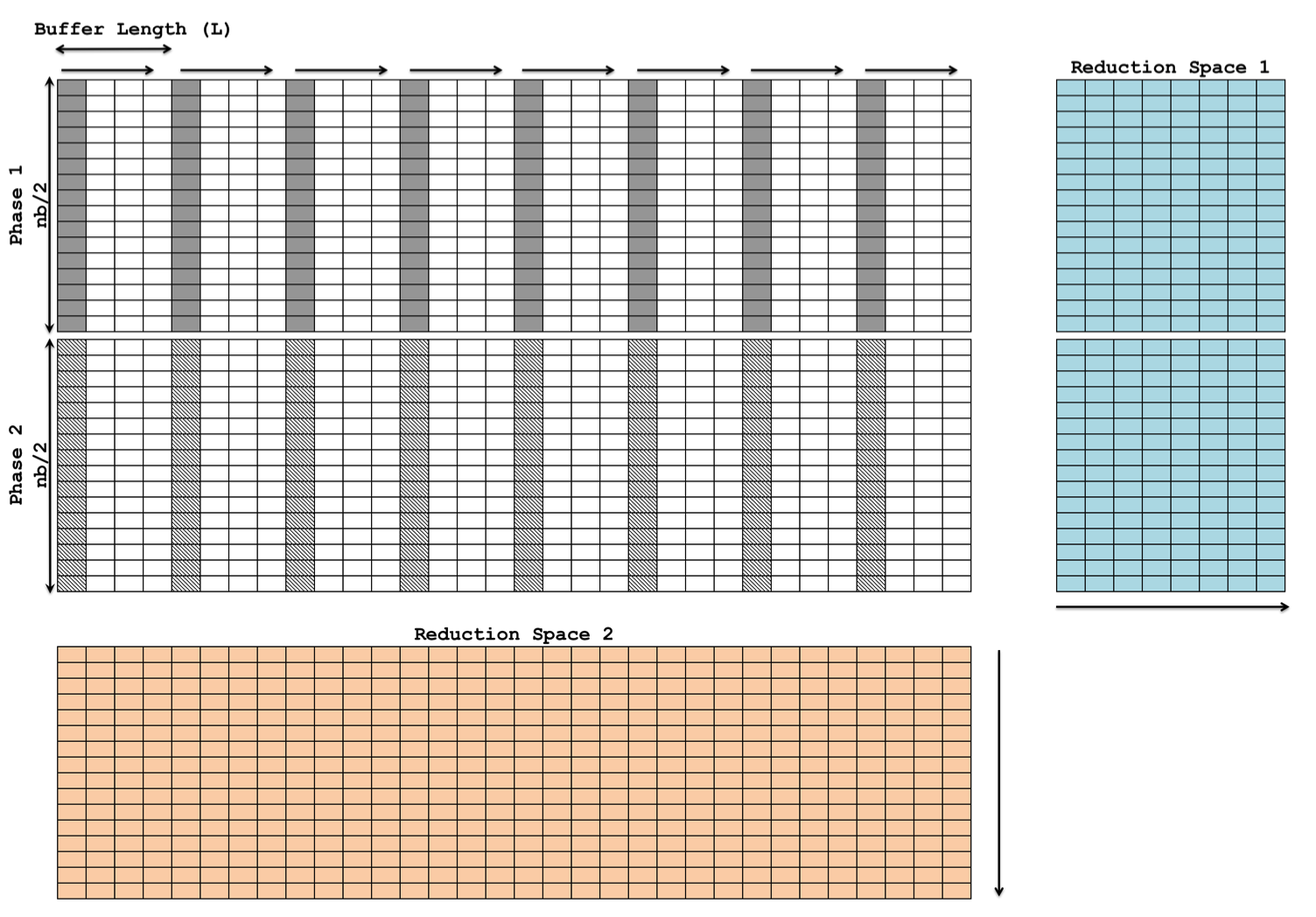
Figure 4: Thread block design.
In GEMV operations, TBs traverse the input matrix either horizontally or vertically depending on whether the matrix is transposed (Figure 5).
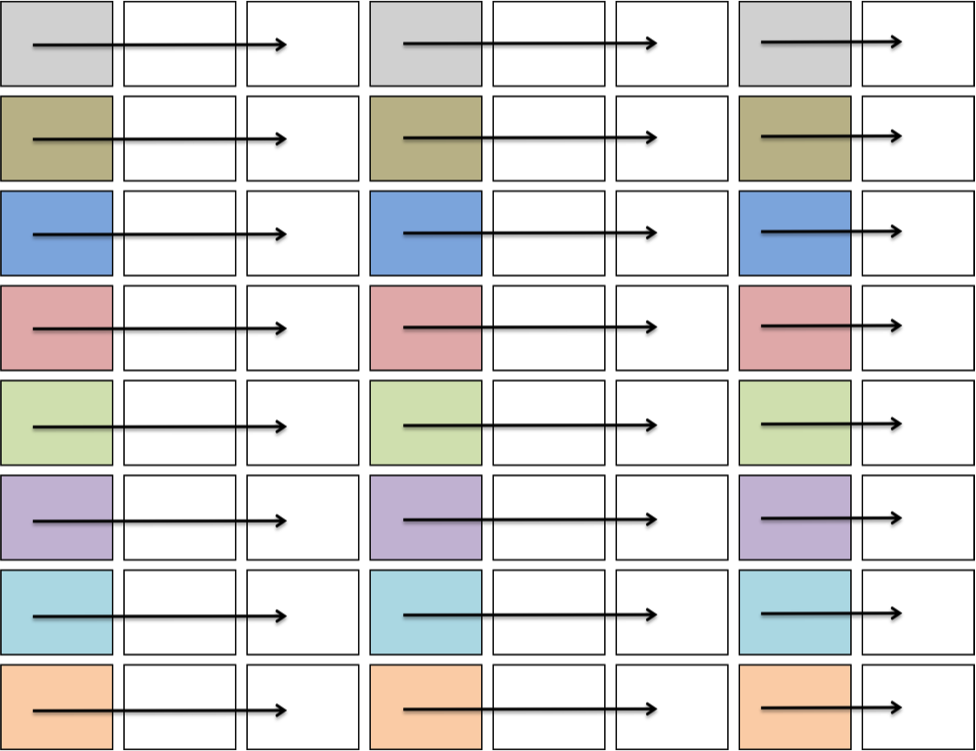
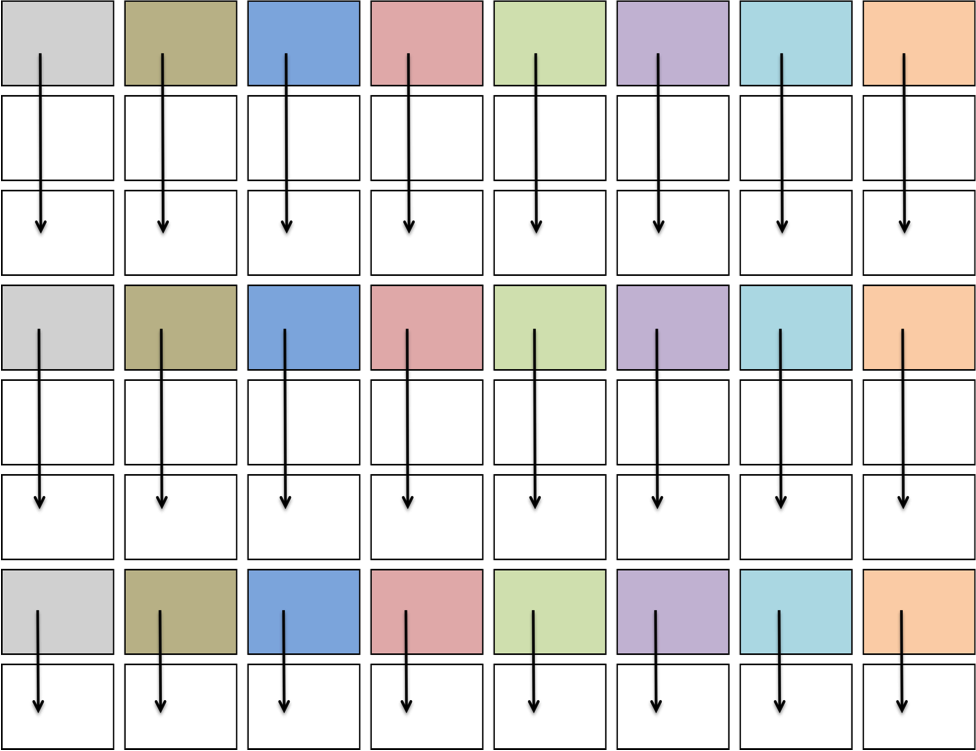
Figure 5: Movement of TBs in a GEMV operation. TBs with the same color share the same value of nb1.
In SYMV/HEMV kernels, TBs process the upper or lower triangular part, with diagonal blocks processed separately (Figure 6).
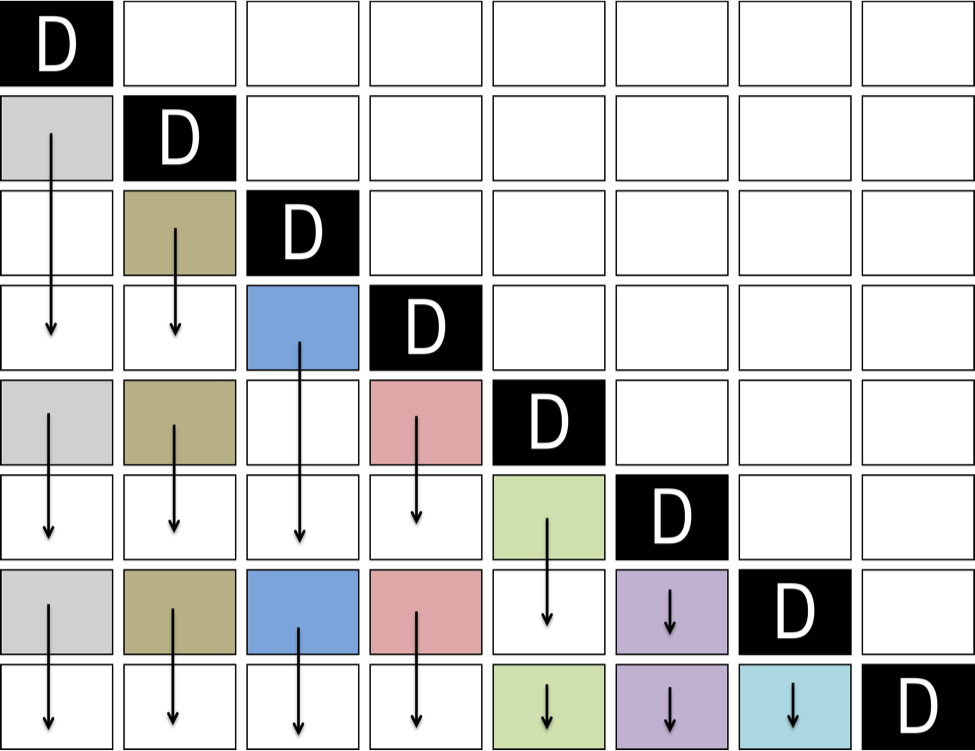
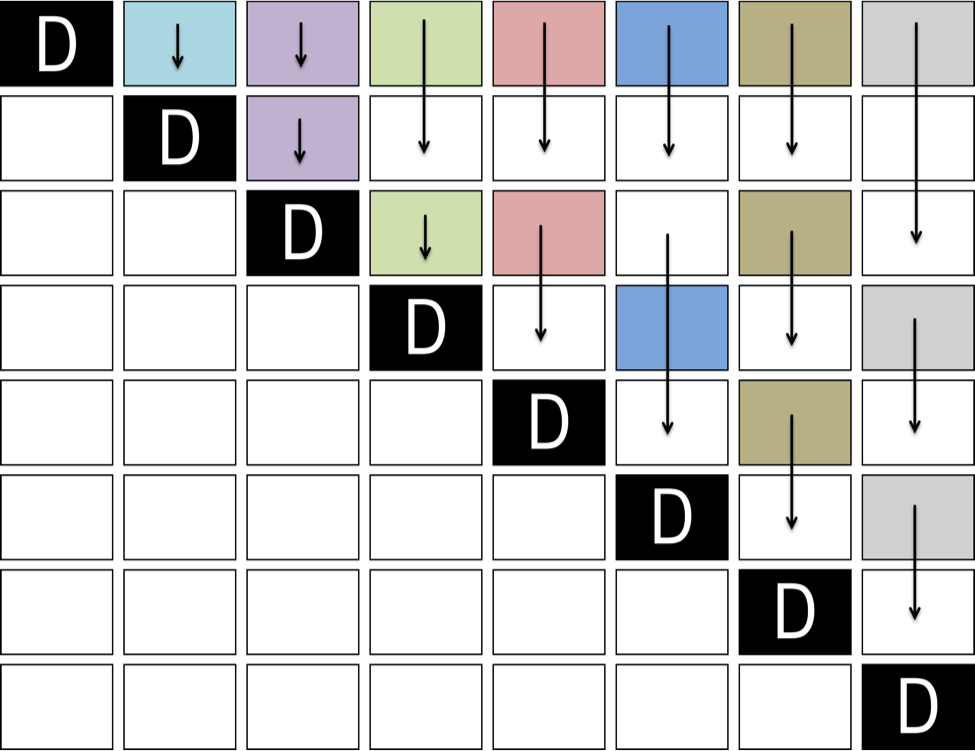
Figure 6: Movement of TBs in a SYMV/HEMV operation. TBs with the same color share the same value of nb2.
For submatrix multiplication, KBLAS introduces new BLAS routines with new interfaces that preserve memory coalesced access by padding the dimensions of the submatrix, which results in extra reads (Figure 7).
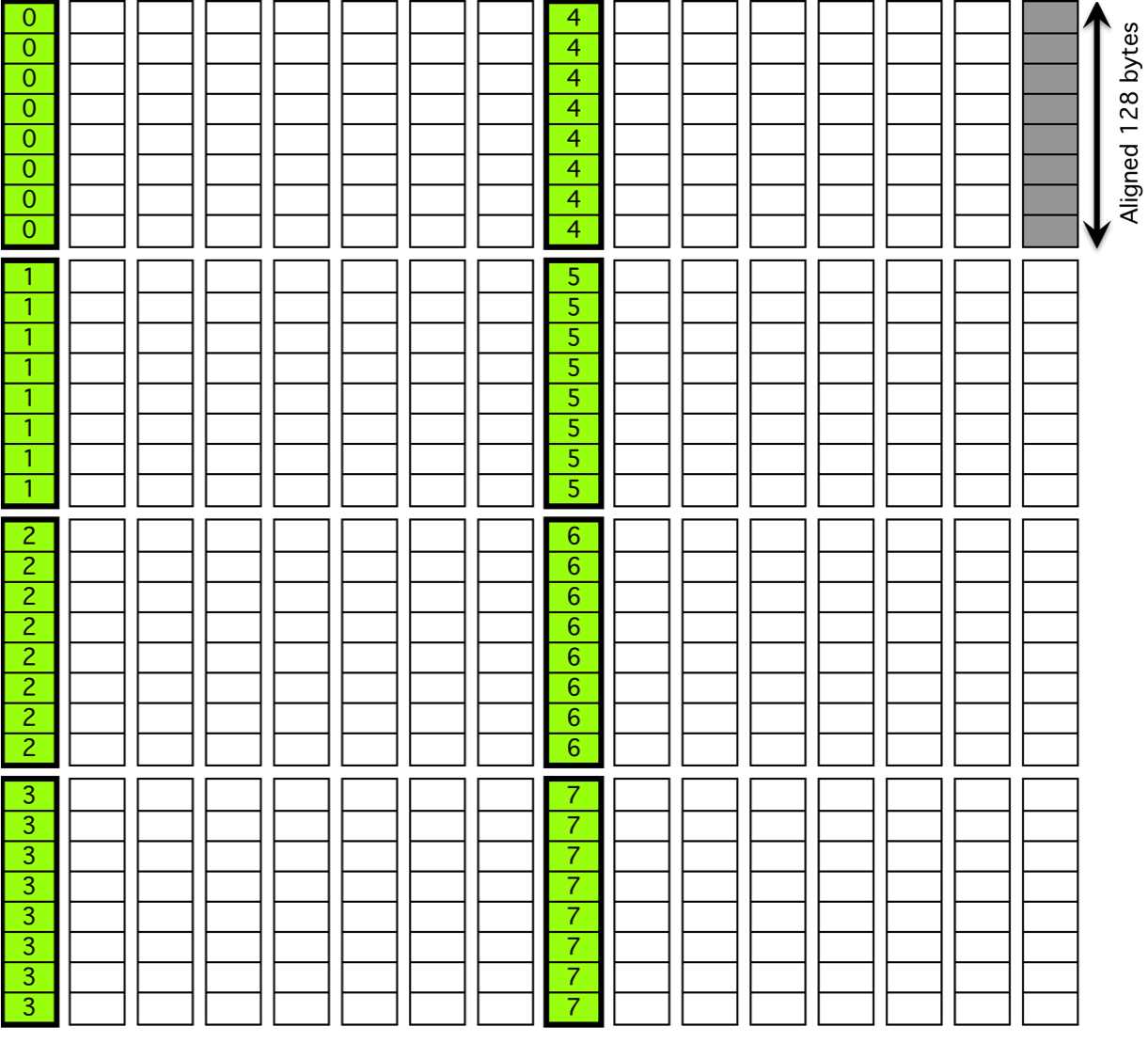
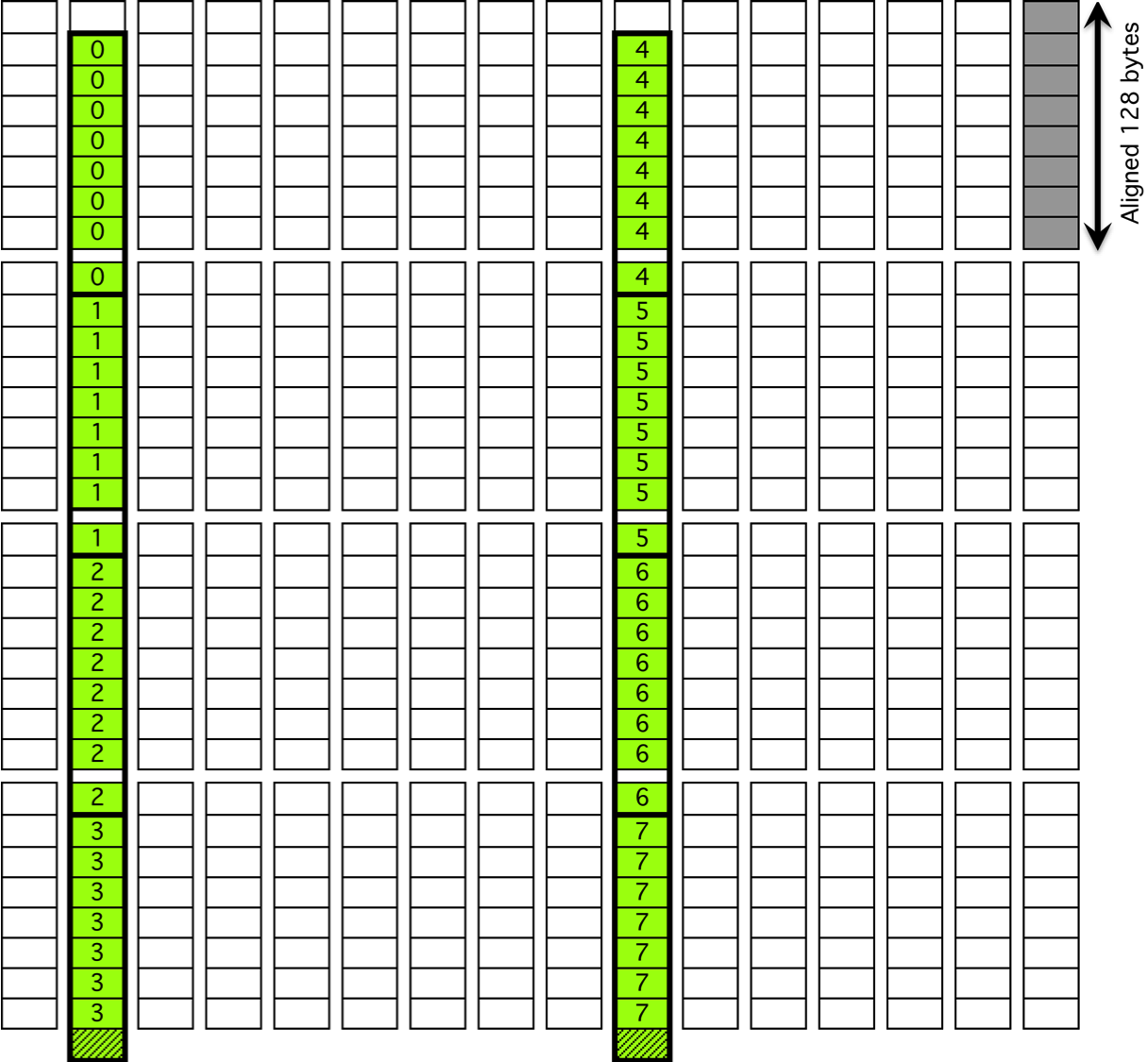
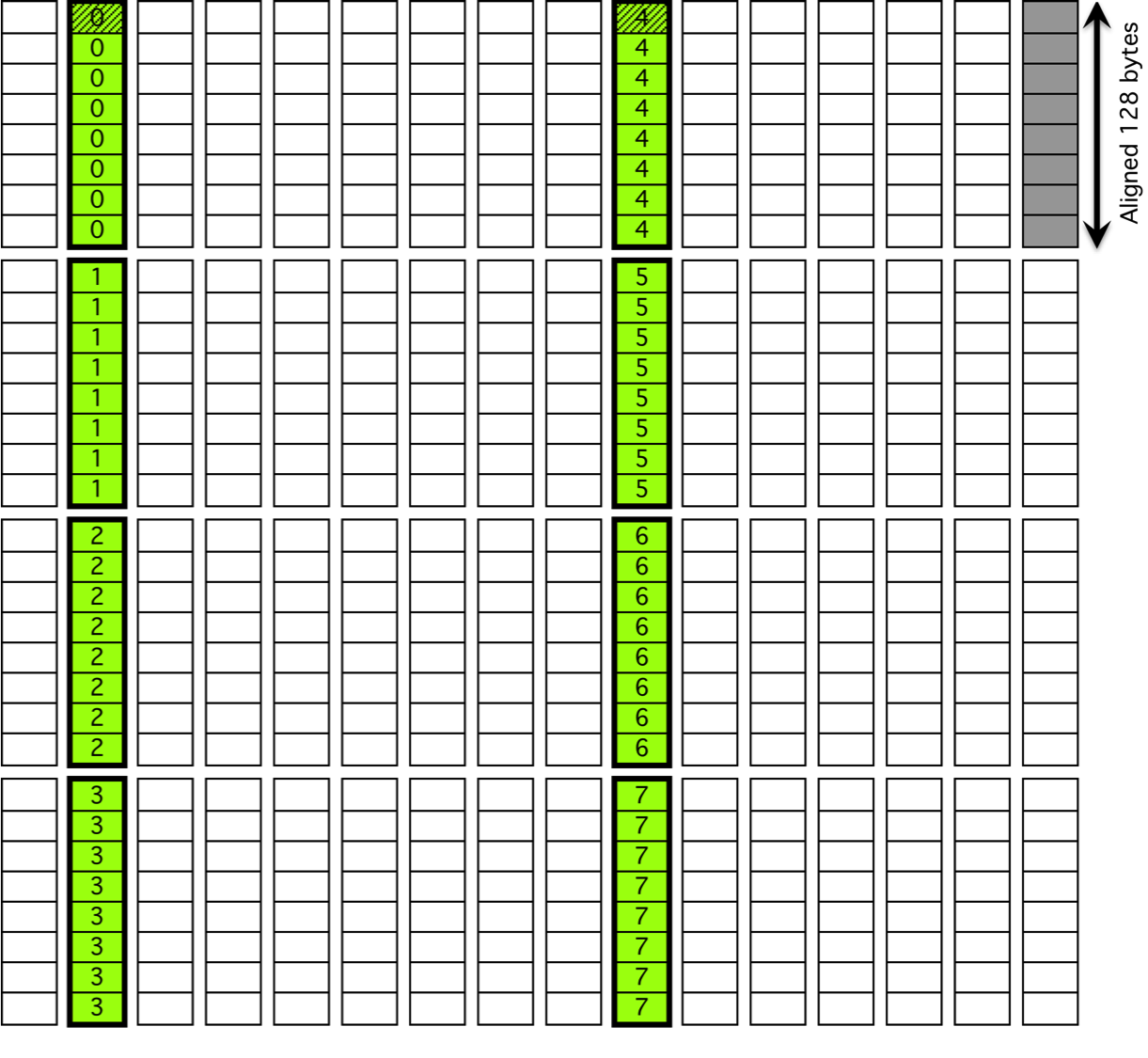
Figure 7: Non-coalesced memory access due to processing a submatrix.
A roofline model is employed to predict sustained peak performance, using the equation nb3, where nb4 is the operational intensity and nb5 is the sustained memory bandwidth. The theoretical peak bandwidth nb6 for a K20c GPU is calculated as 208 GB/s, while the experimentally obtained sustained memory bandwidth nb7 using the STREAM benchmark is 175.24 GB/s (ECC off).
KBLAS outperforms existing implementations, achieving up to 50% and 60% speedup on single and multi-GPU systems, respectively. GEMV performance is shown in Figure 8.
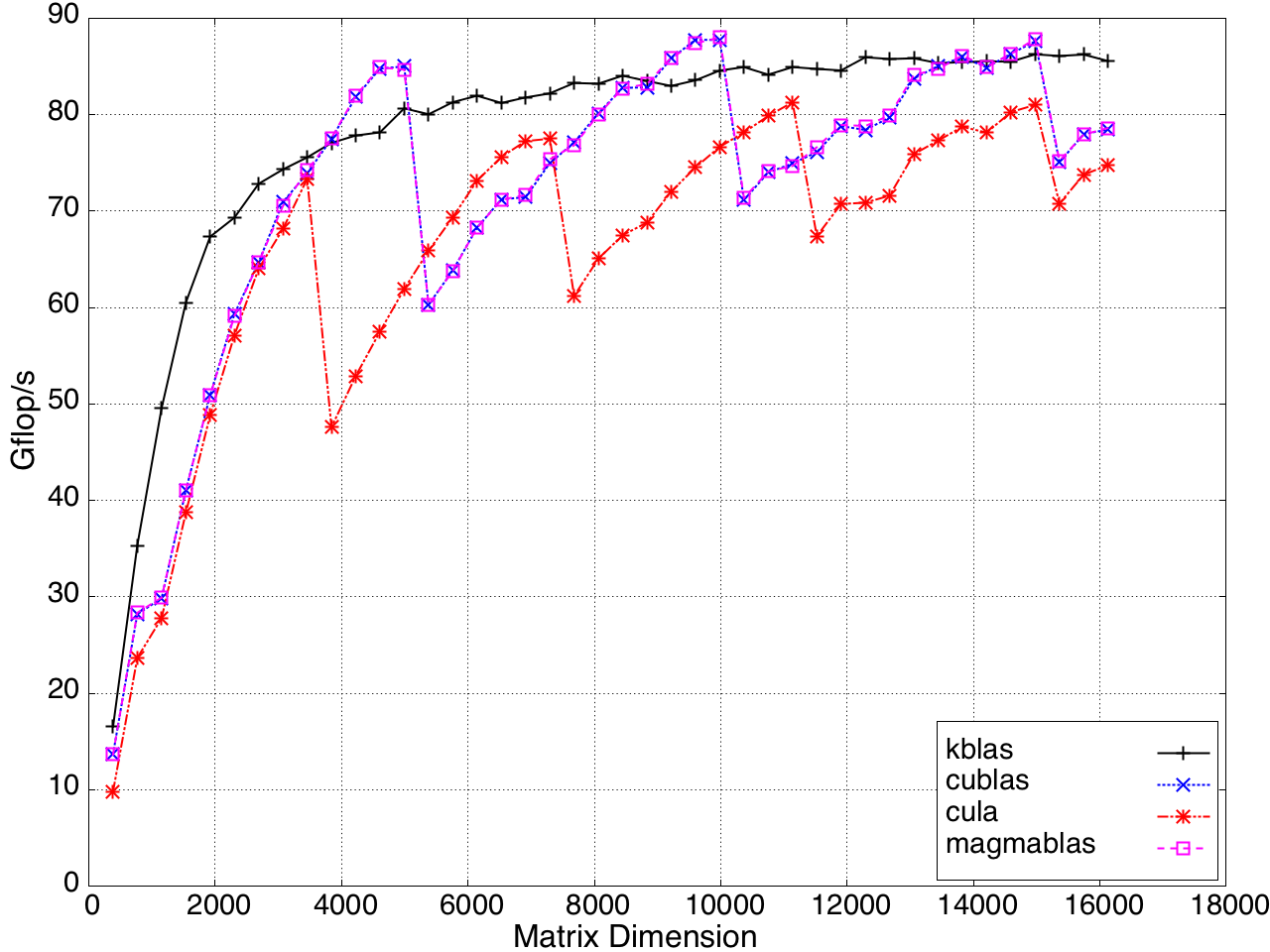
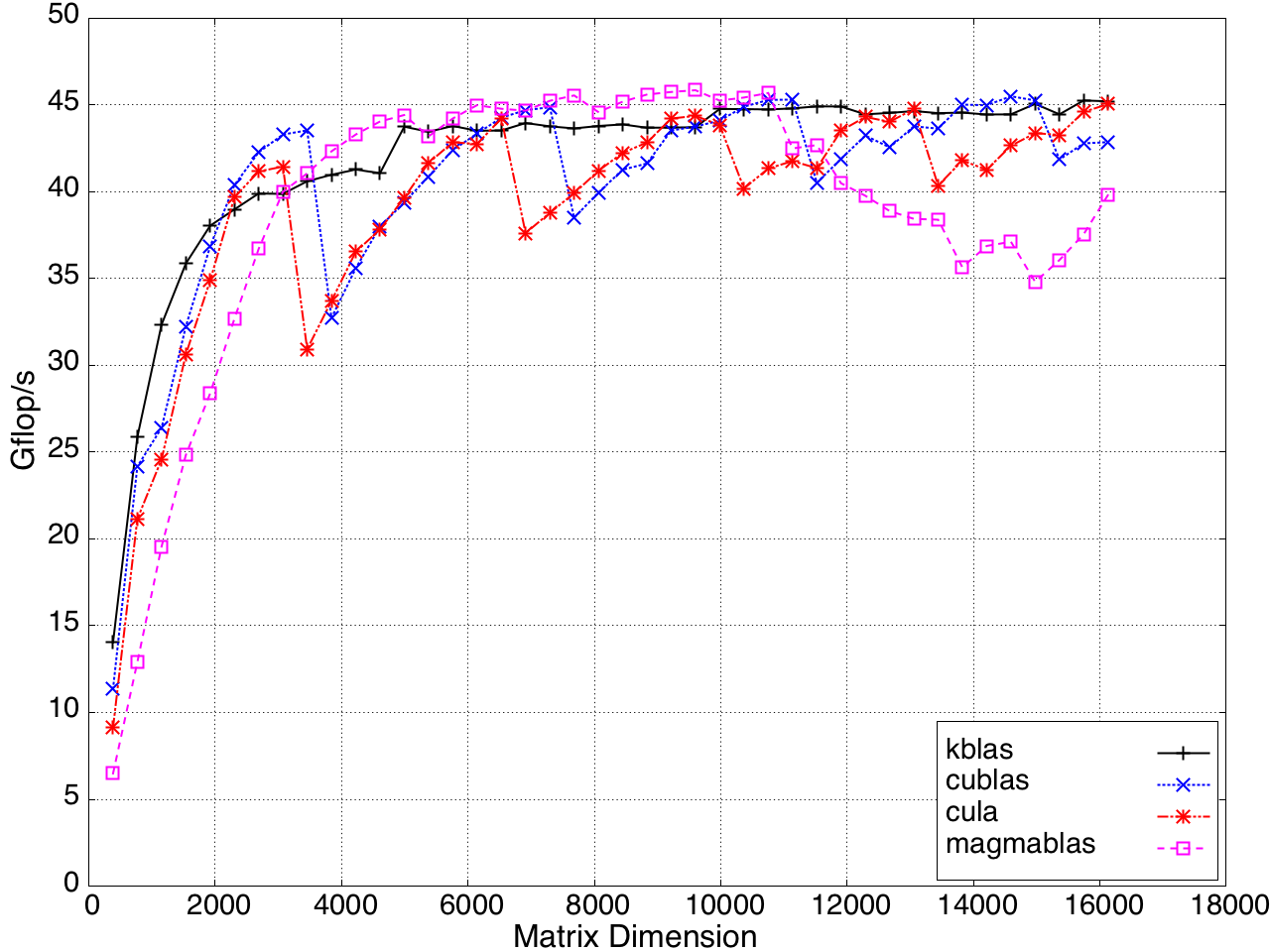
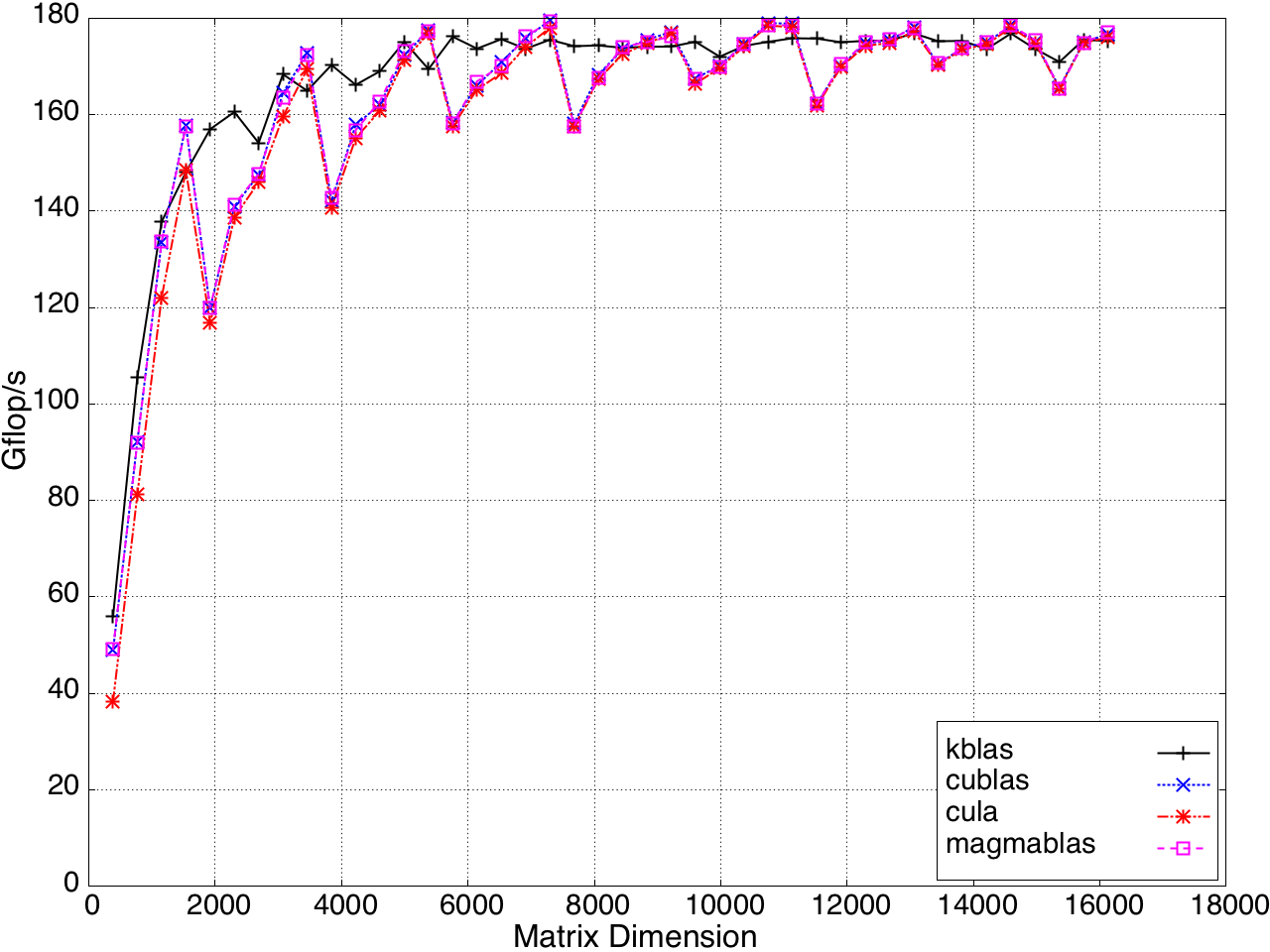
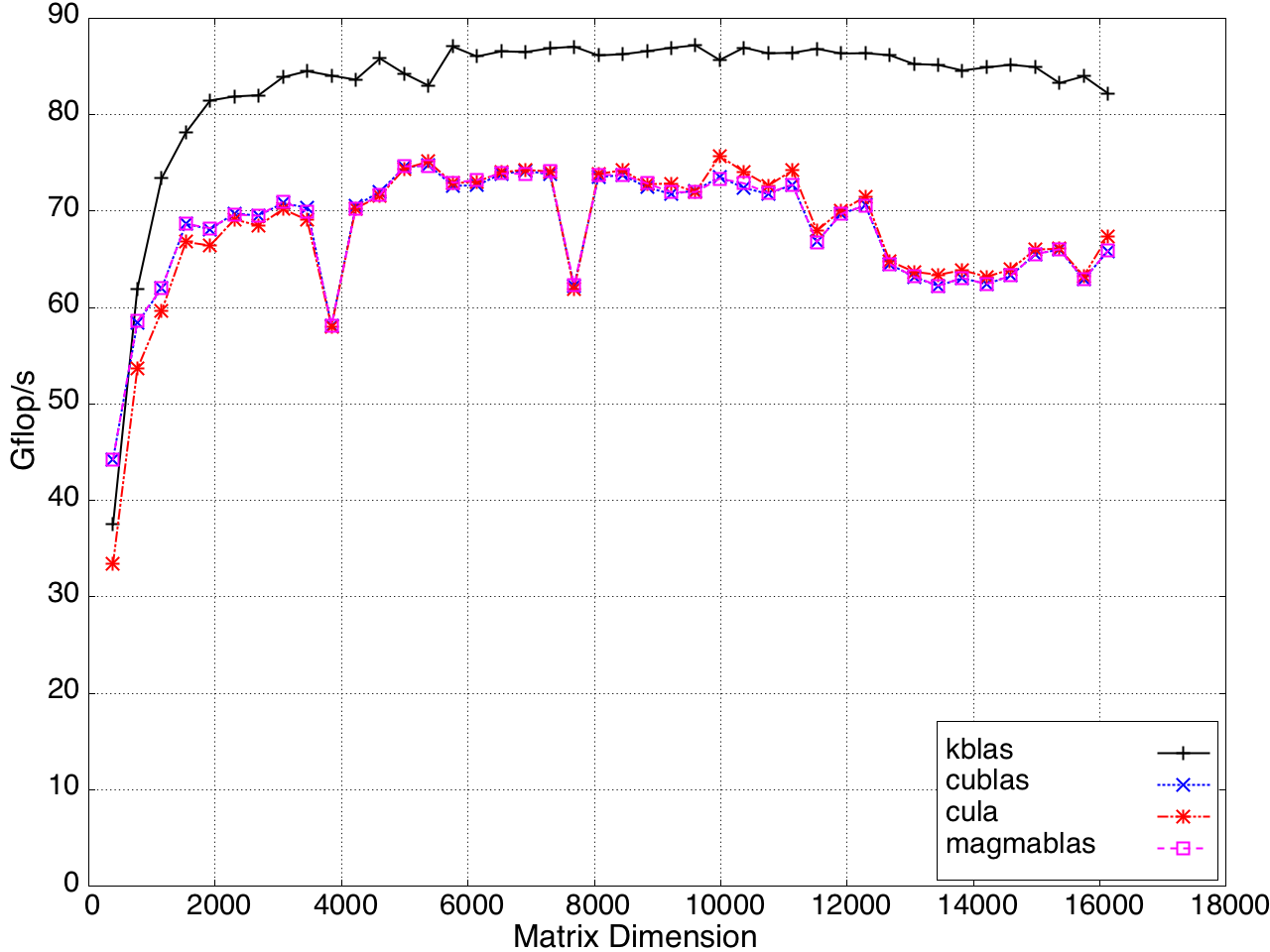
Figure 8: GEMV Performance on a K20c GPU, ECC off.
SYMV/HEMV performance is shown in Figure 10.
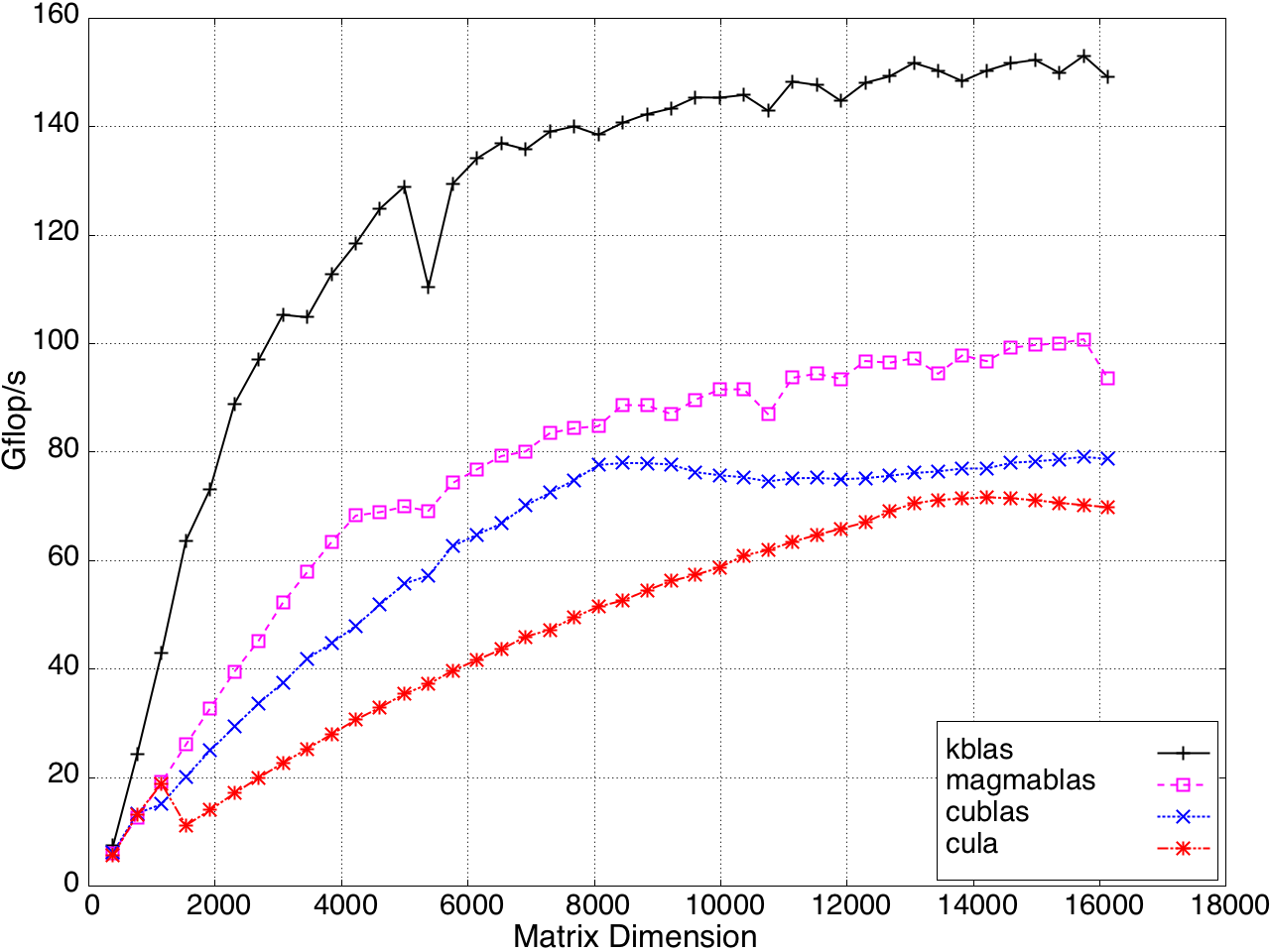
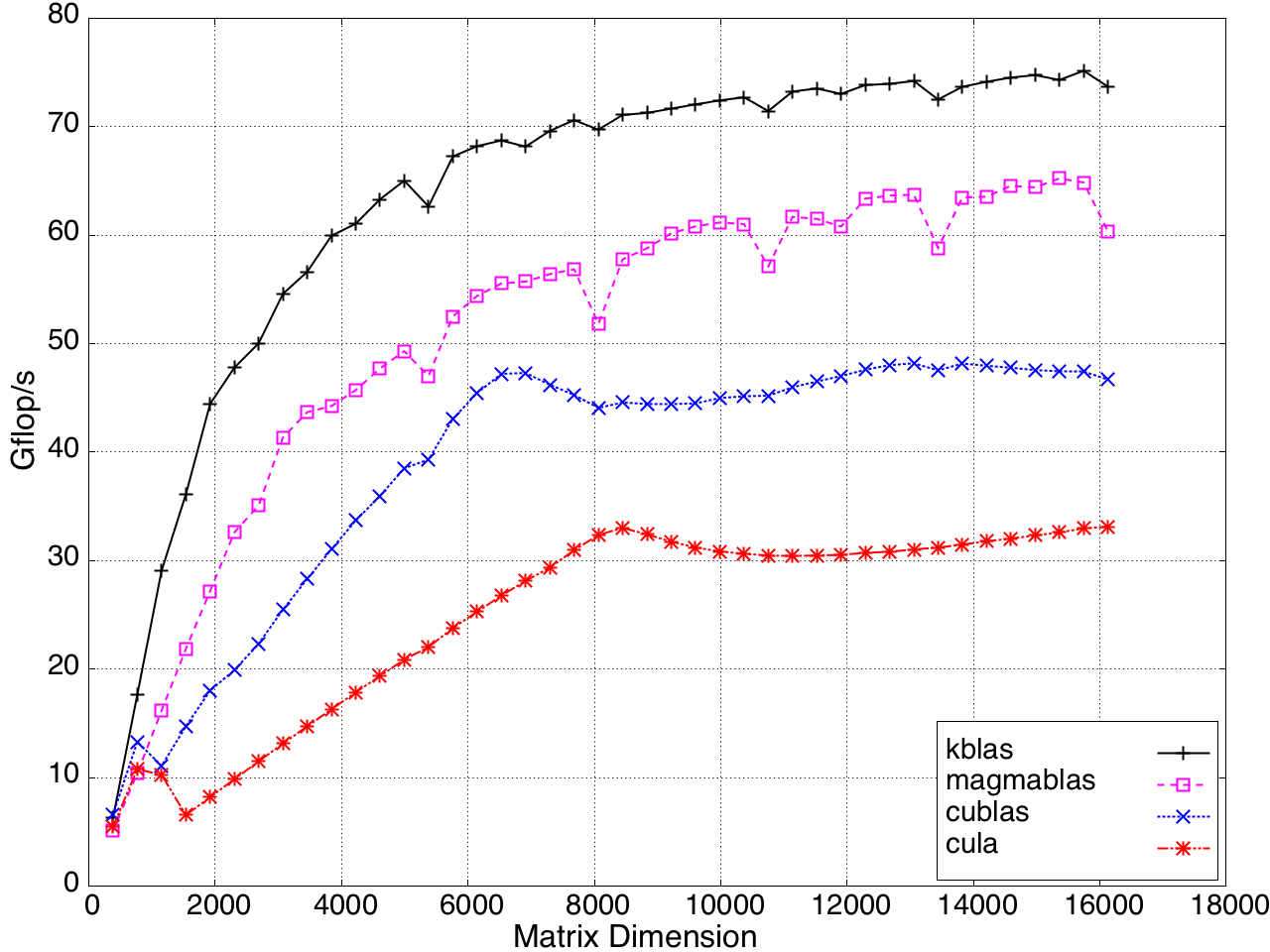
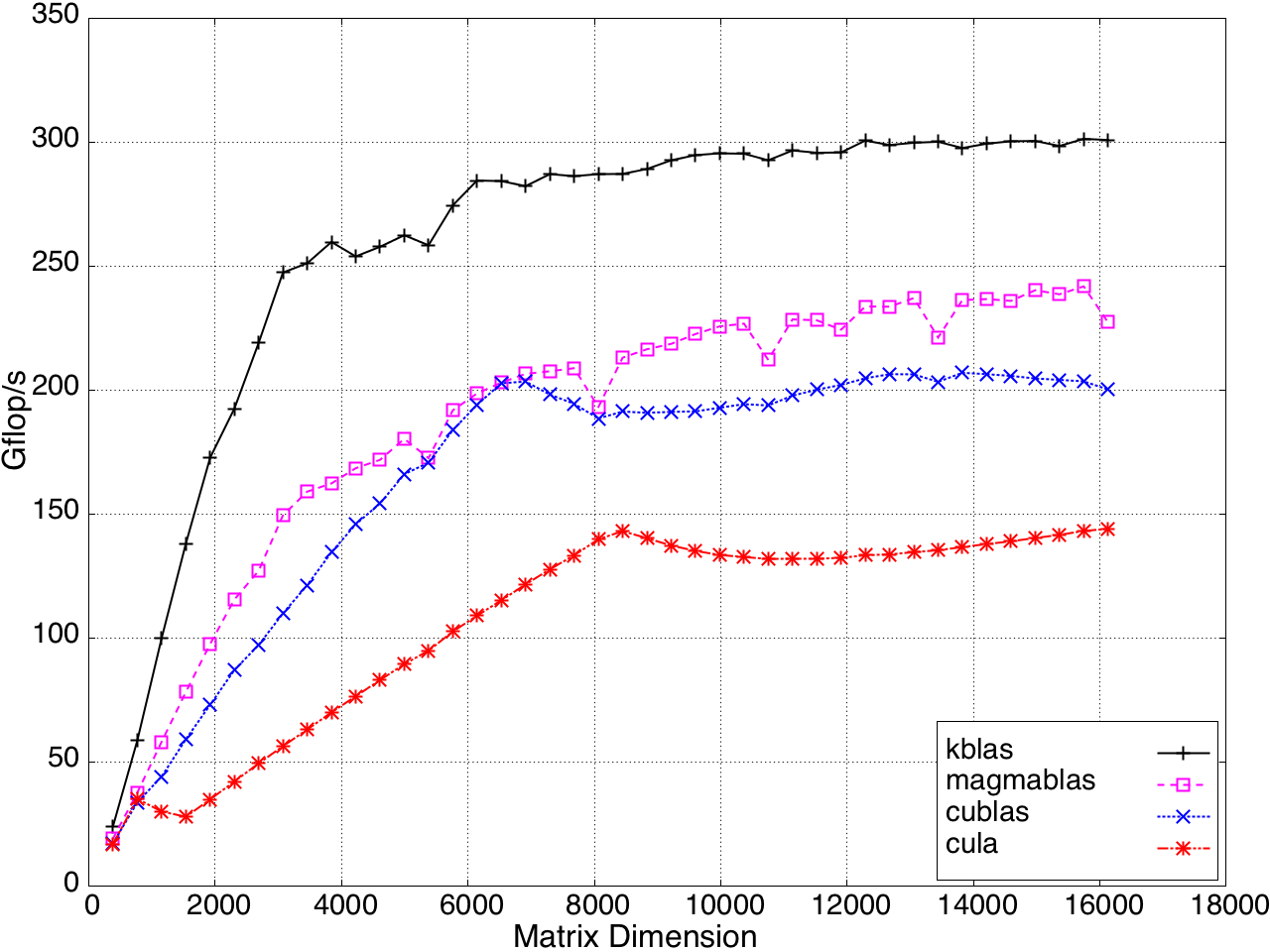
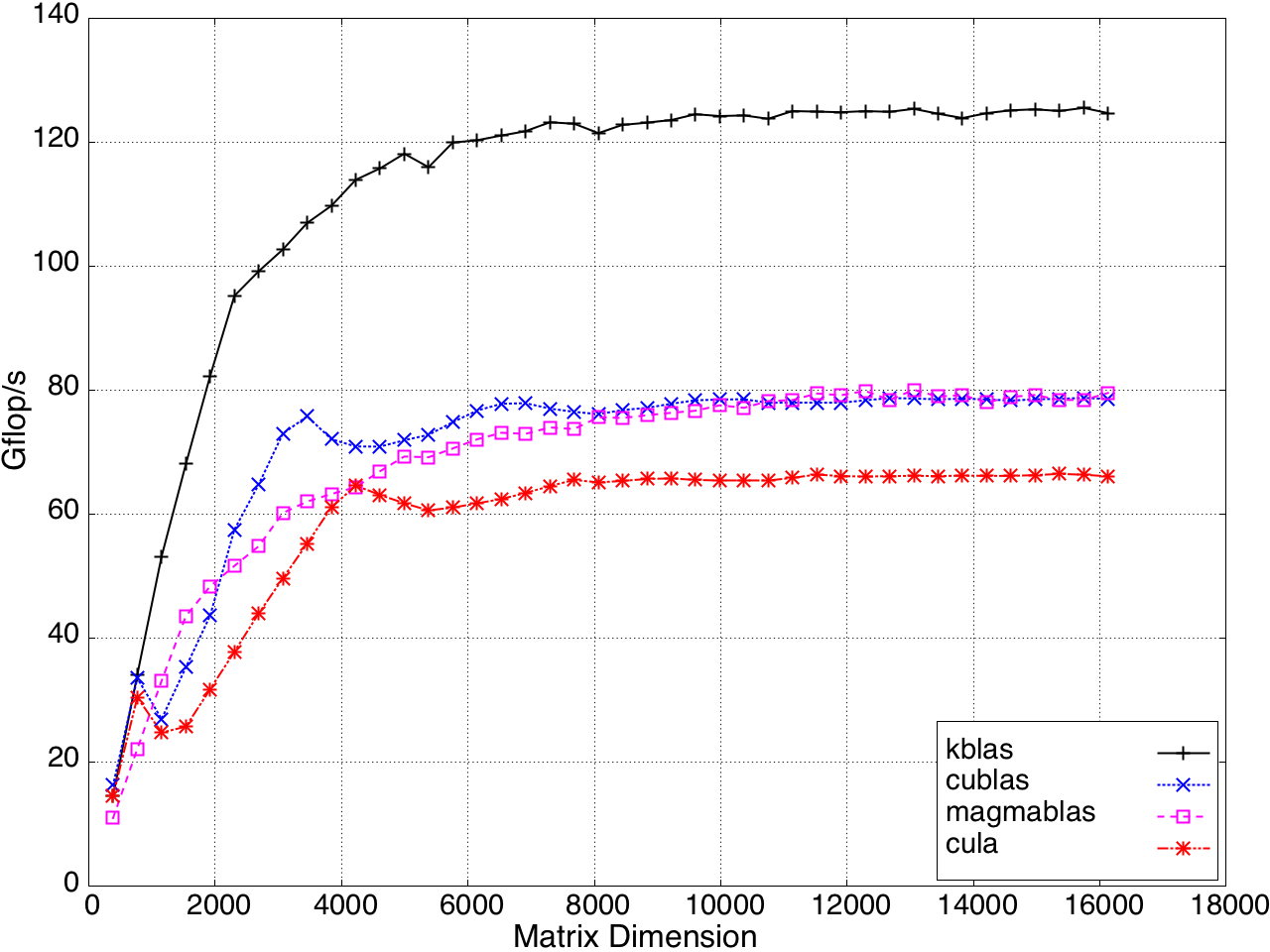
Figure 9: SYMV/HEMV Performance on a K20c GPU, ECC off.
Performance for submatrix multiplication is shown in Figures 11 and 12.
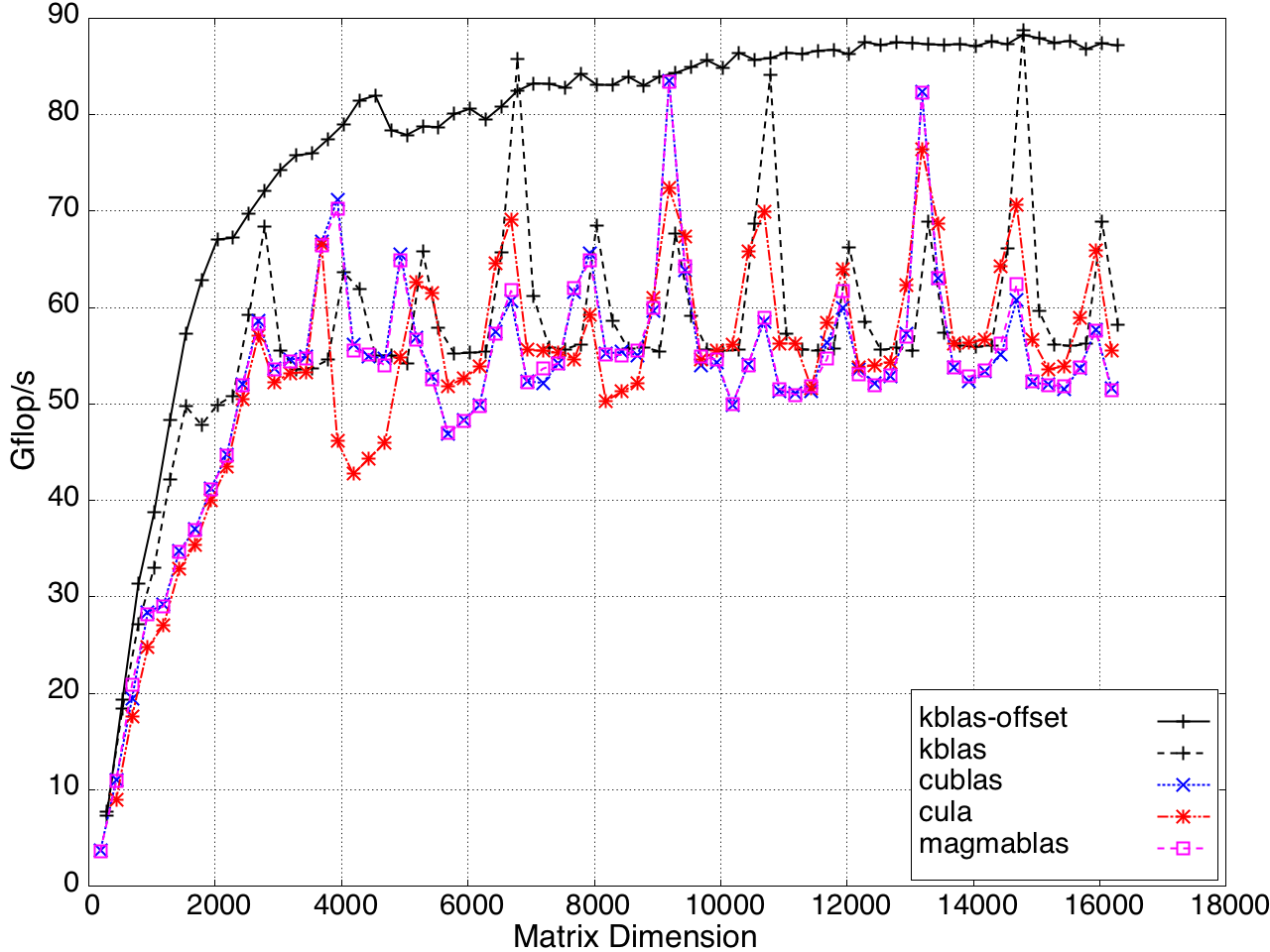
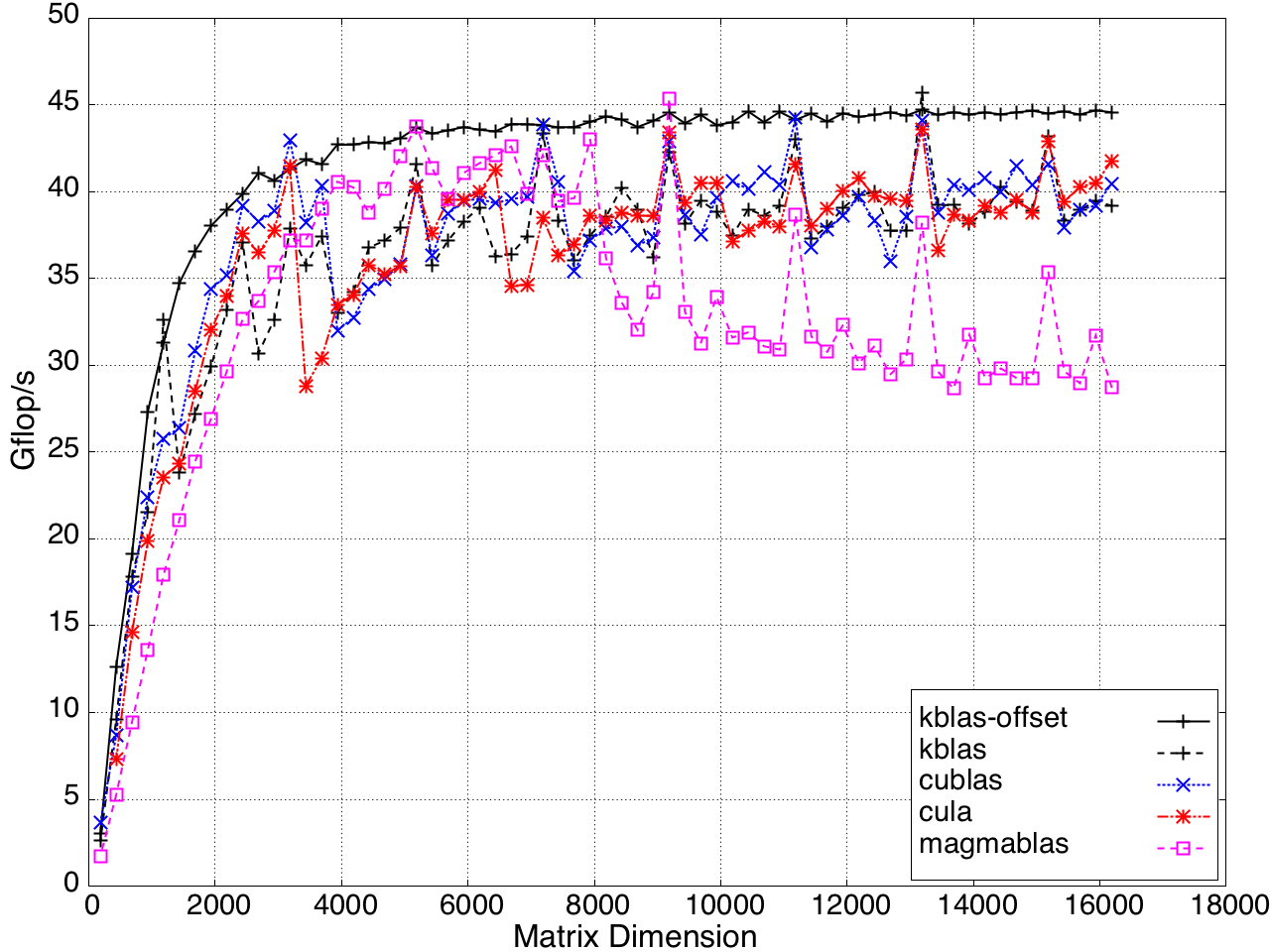
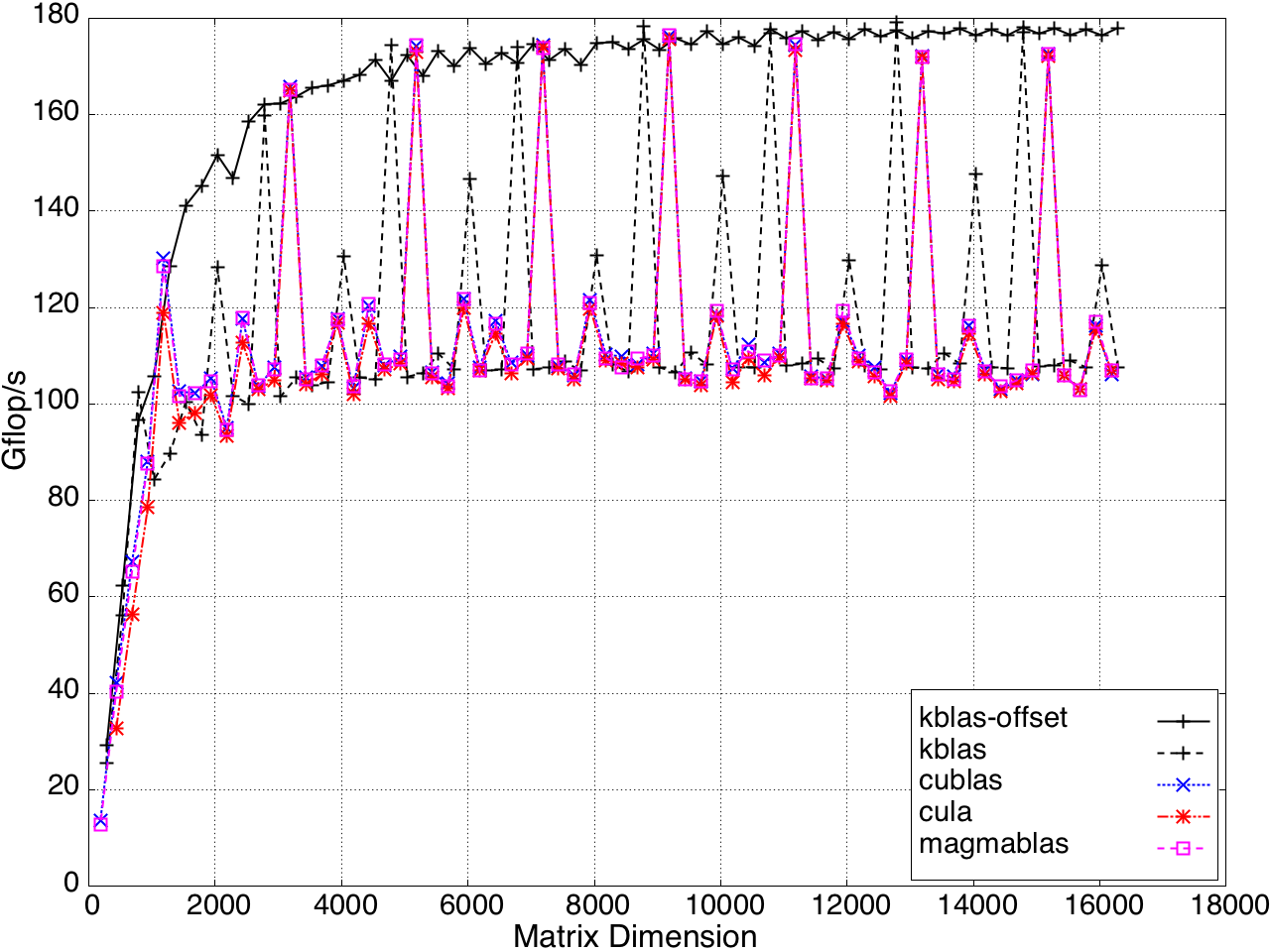
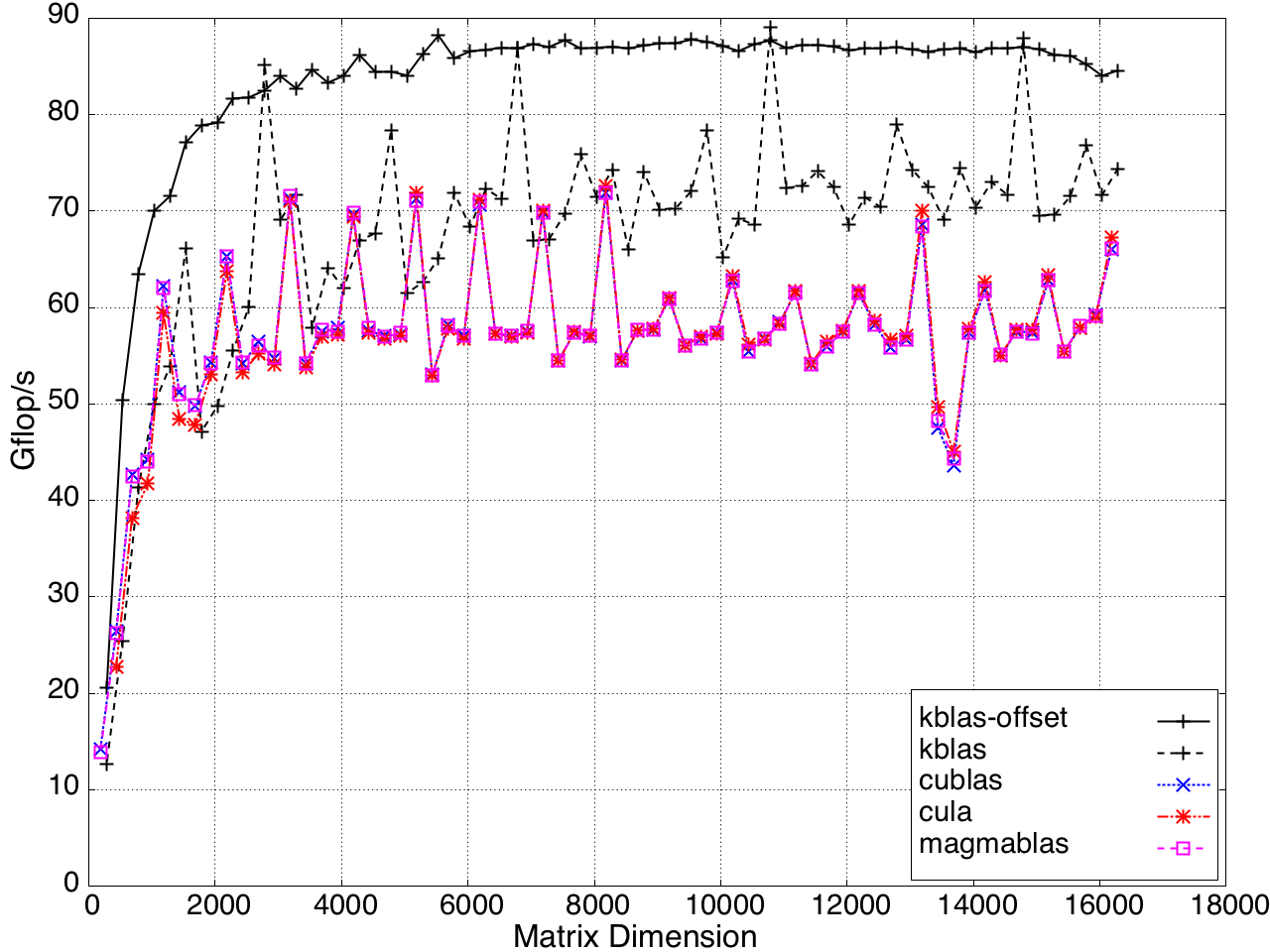
Figure 10: Performance of GEMV by a submatrix on a K20c GPU, ECC off.
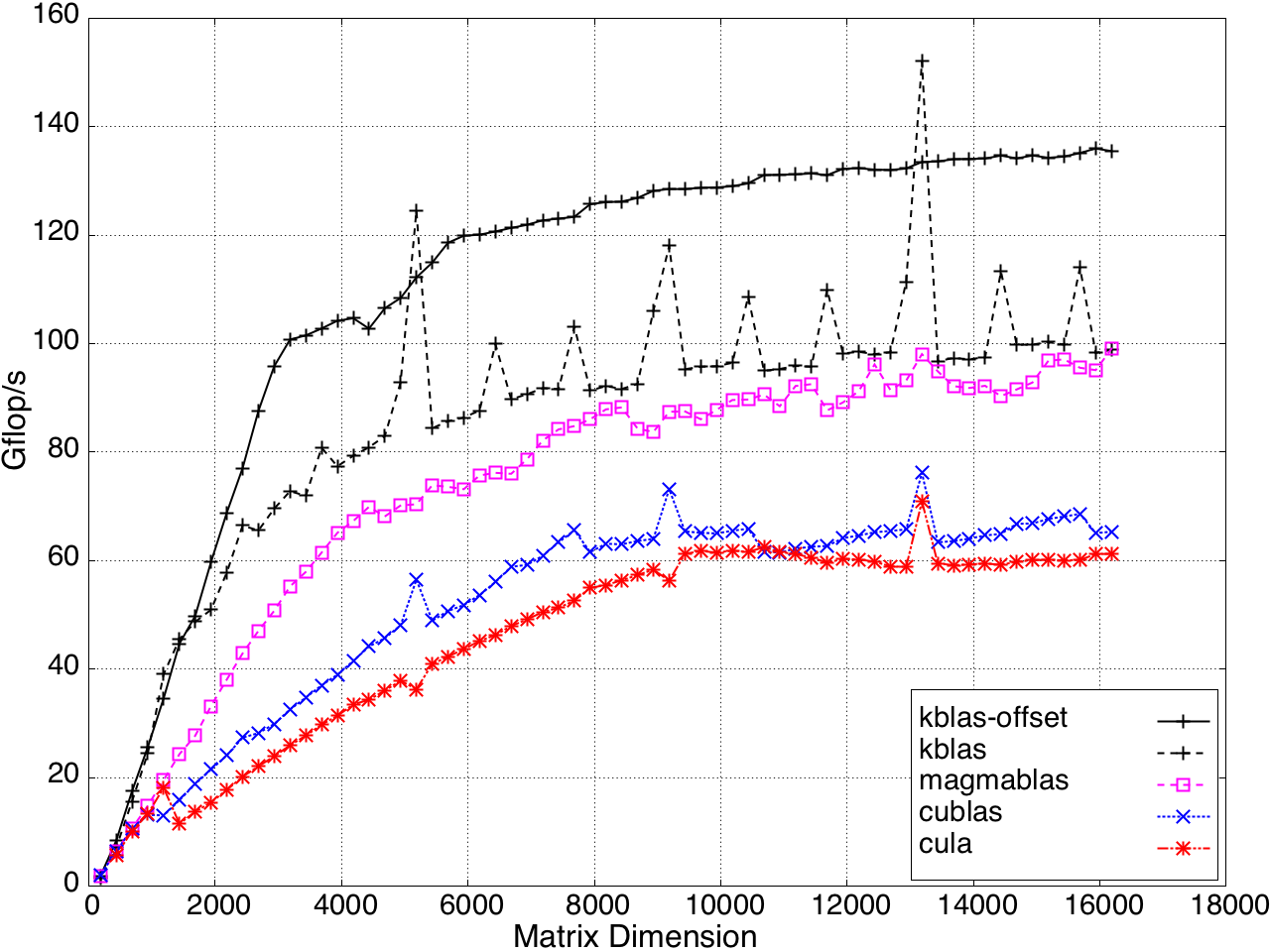
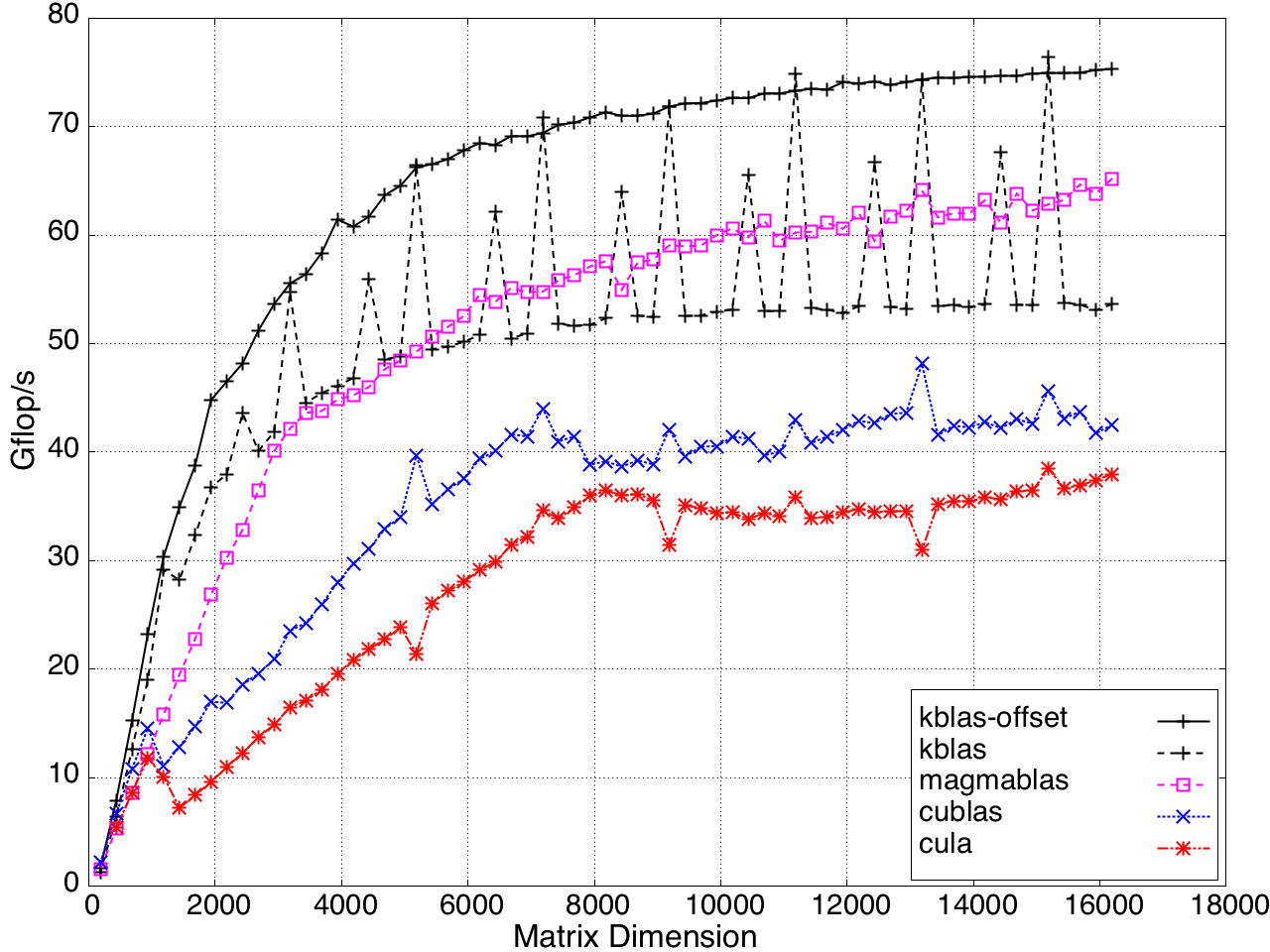
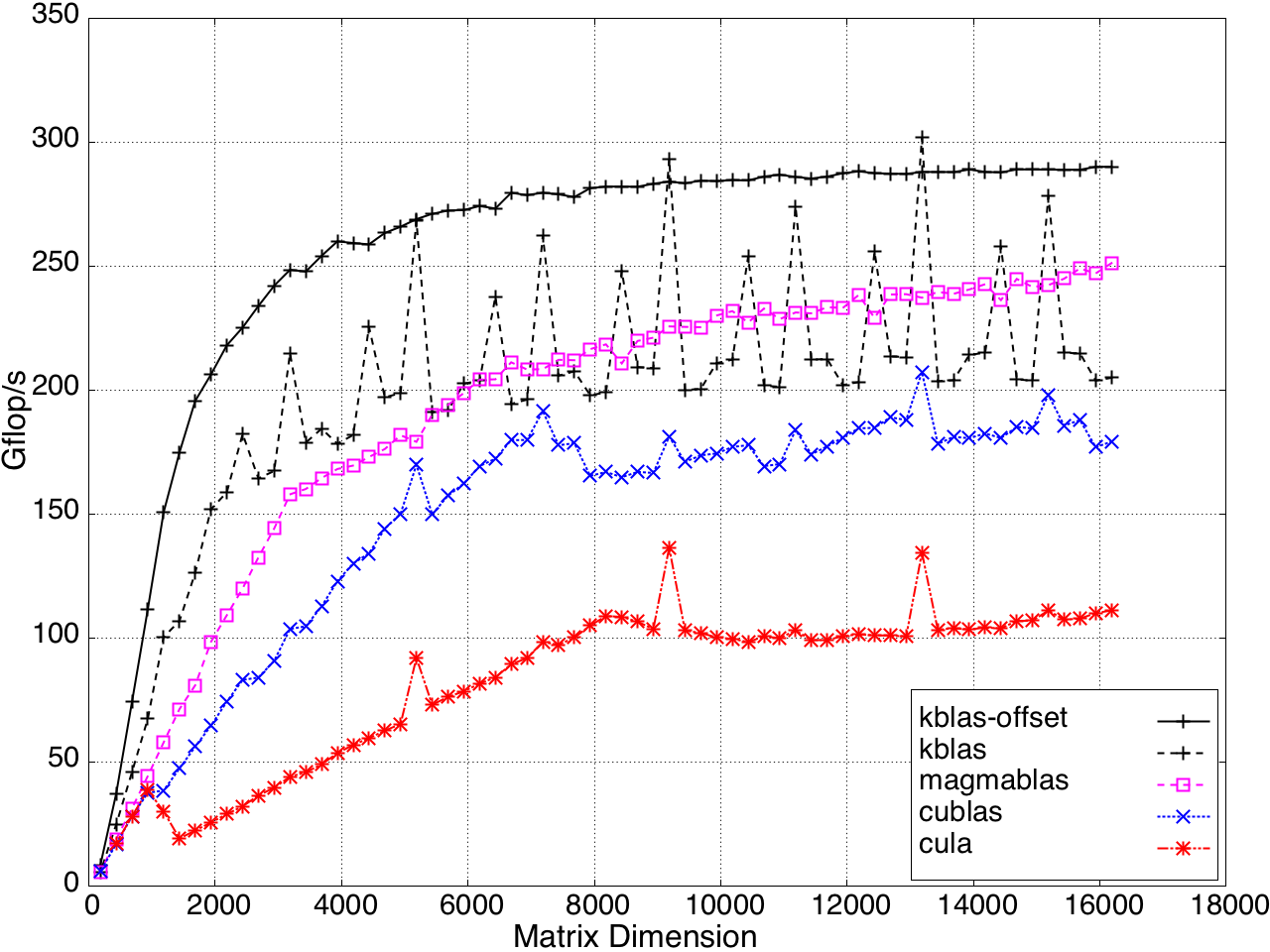
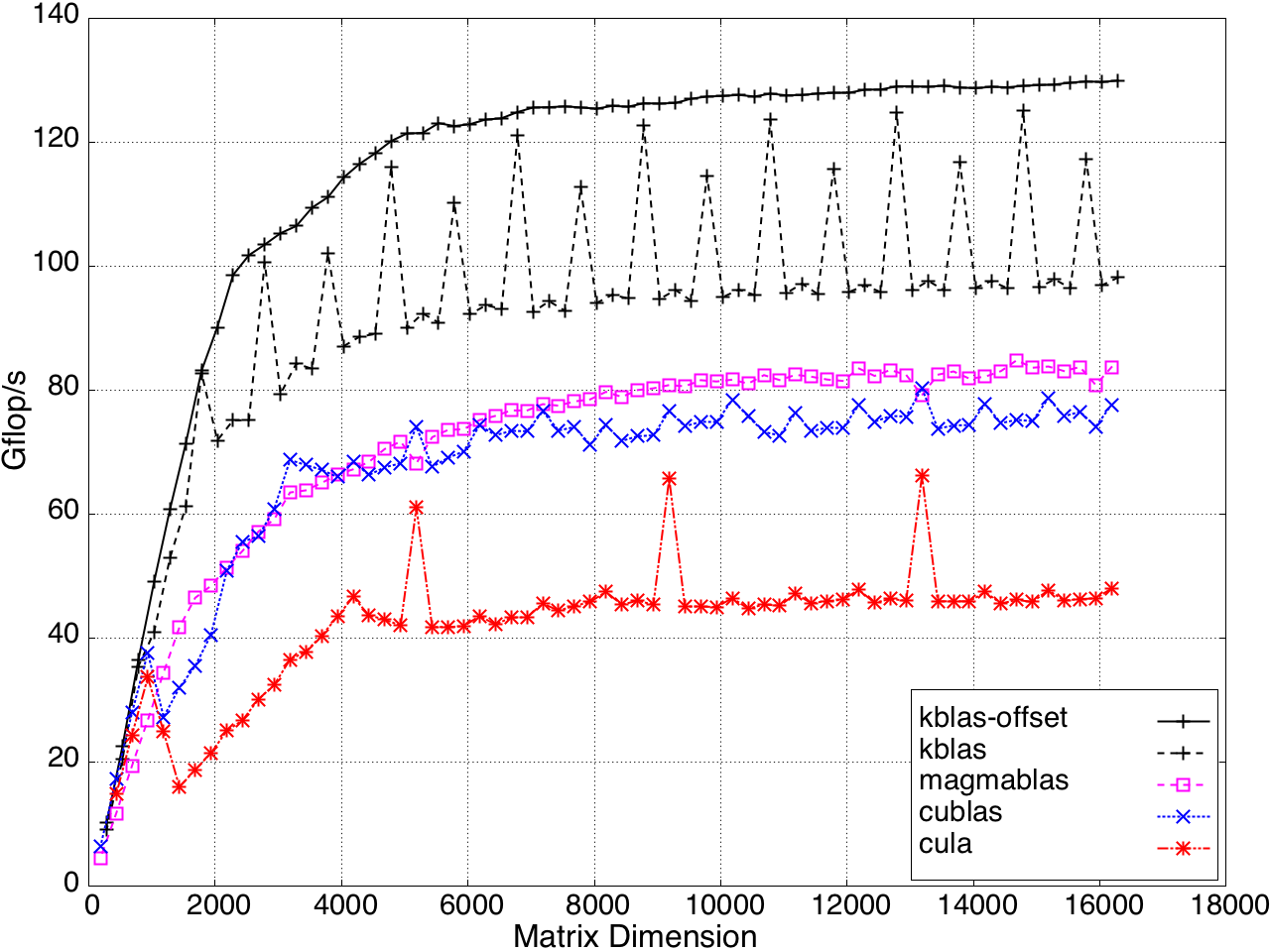
Figure 11: Performance of SYMV/HEMV by a submatrix on a K20c GPU, ECC off.
Multi-GPU performance for GEMV and SYMV/HEMV are shown in Figures 13 and 14.
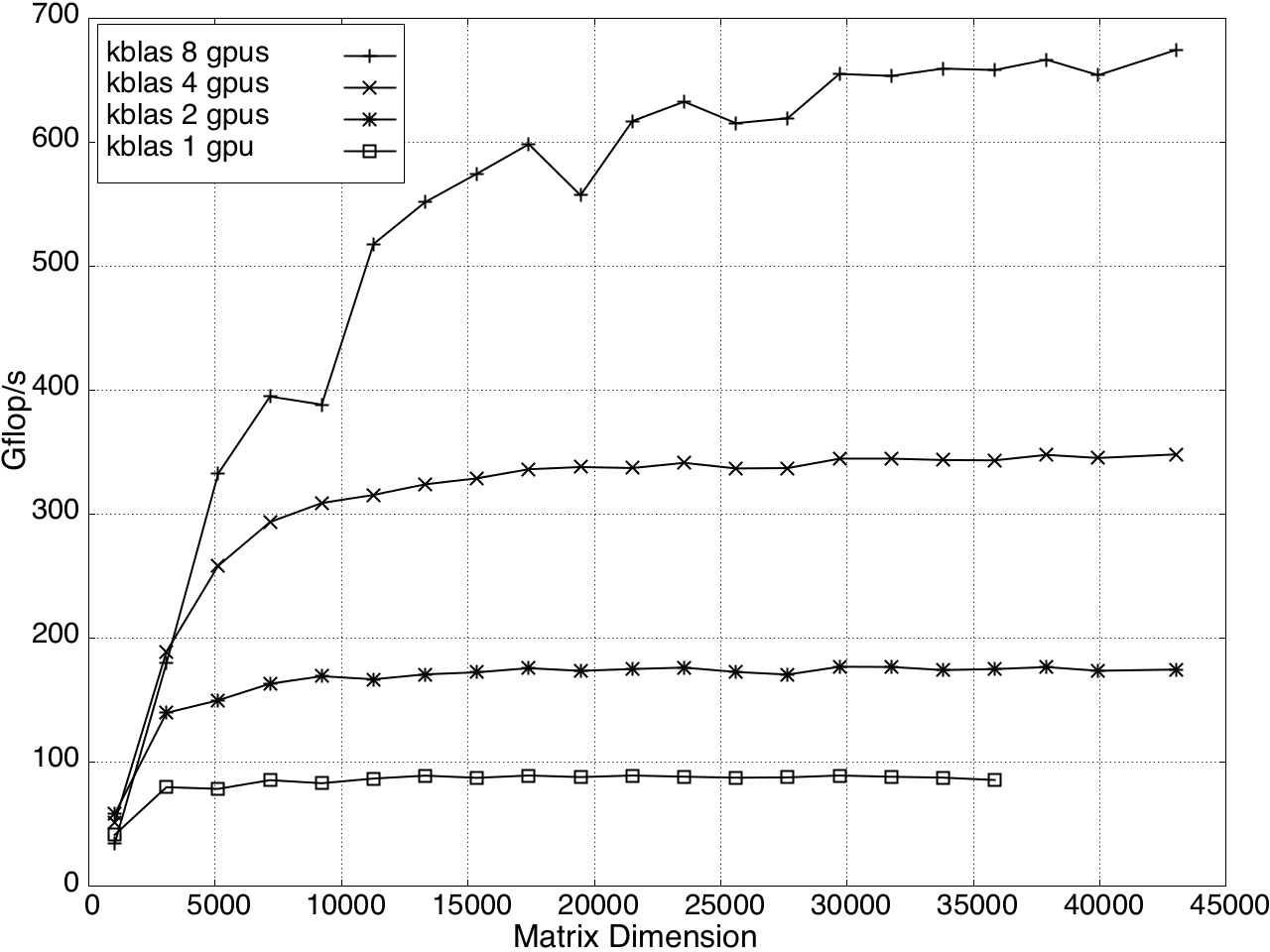
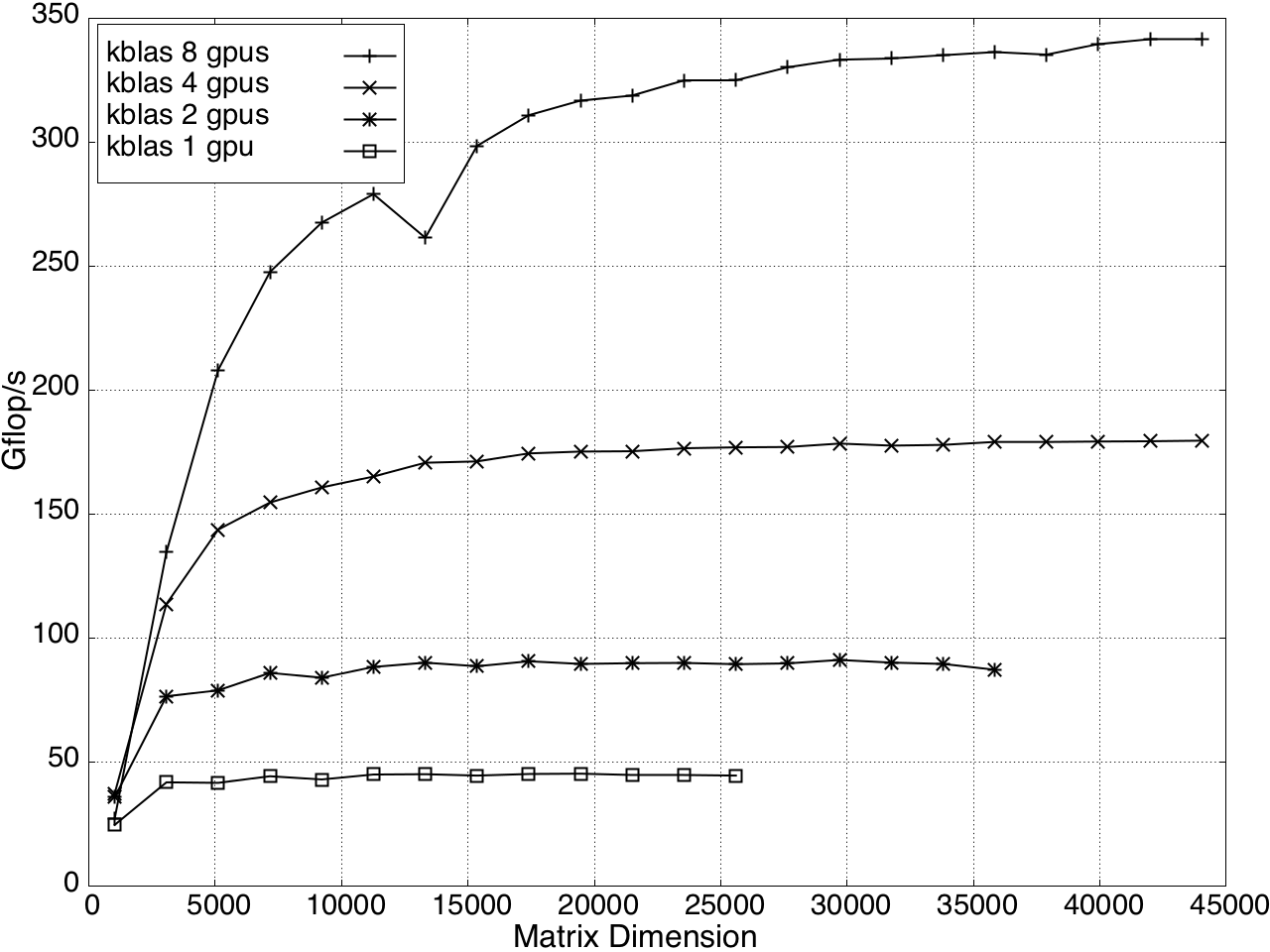
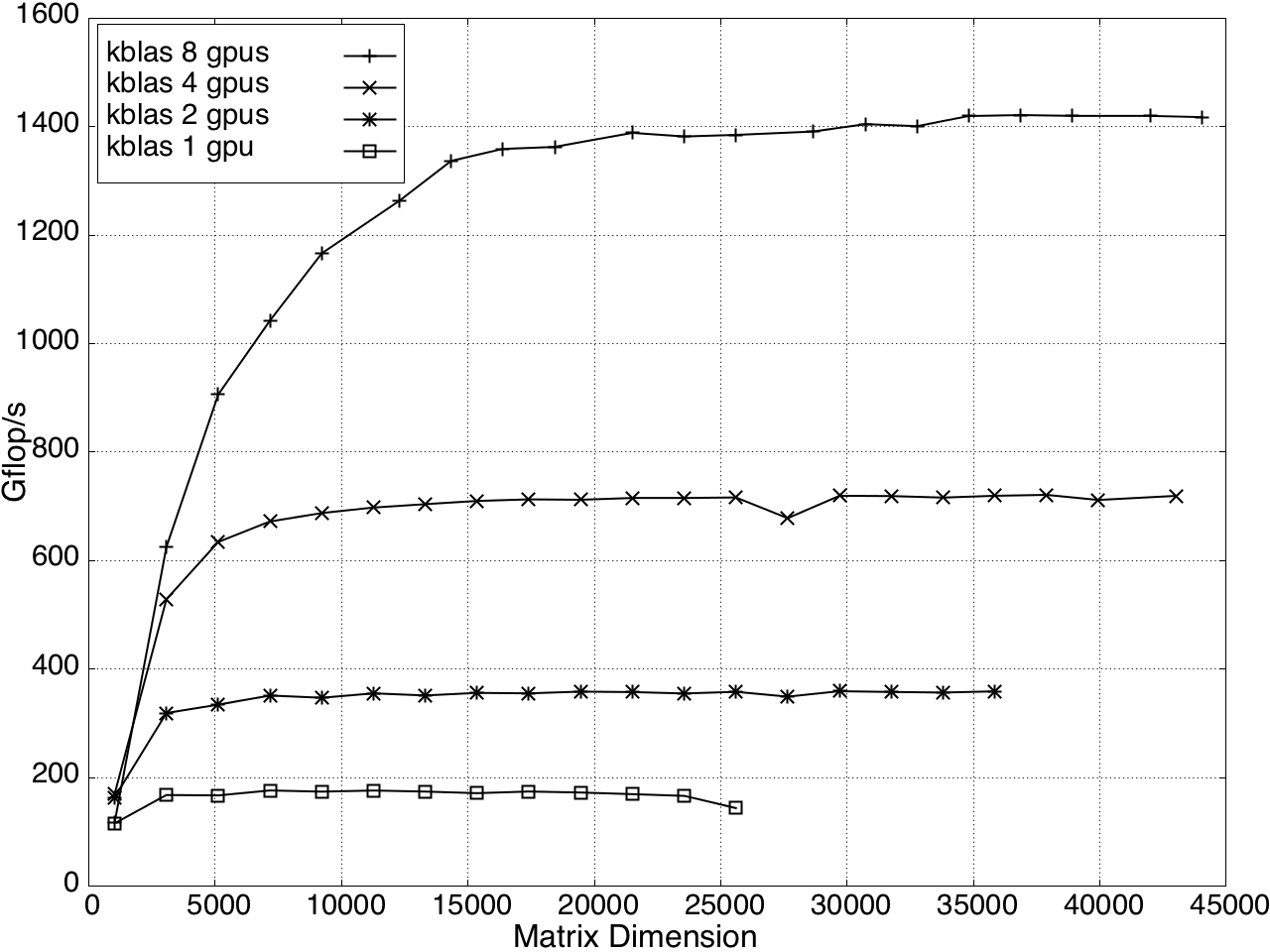
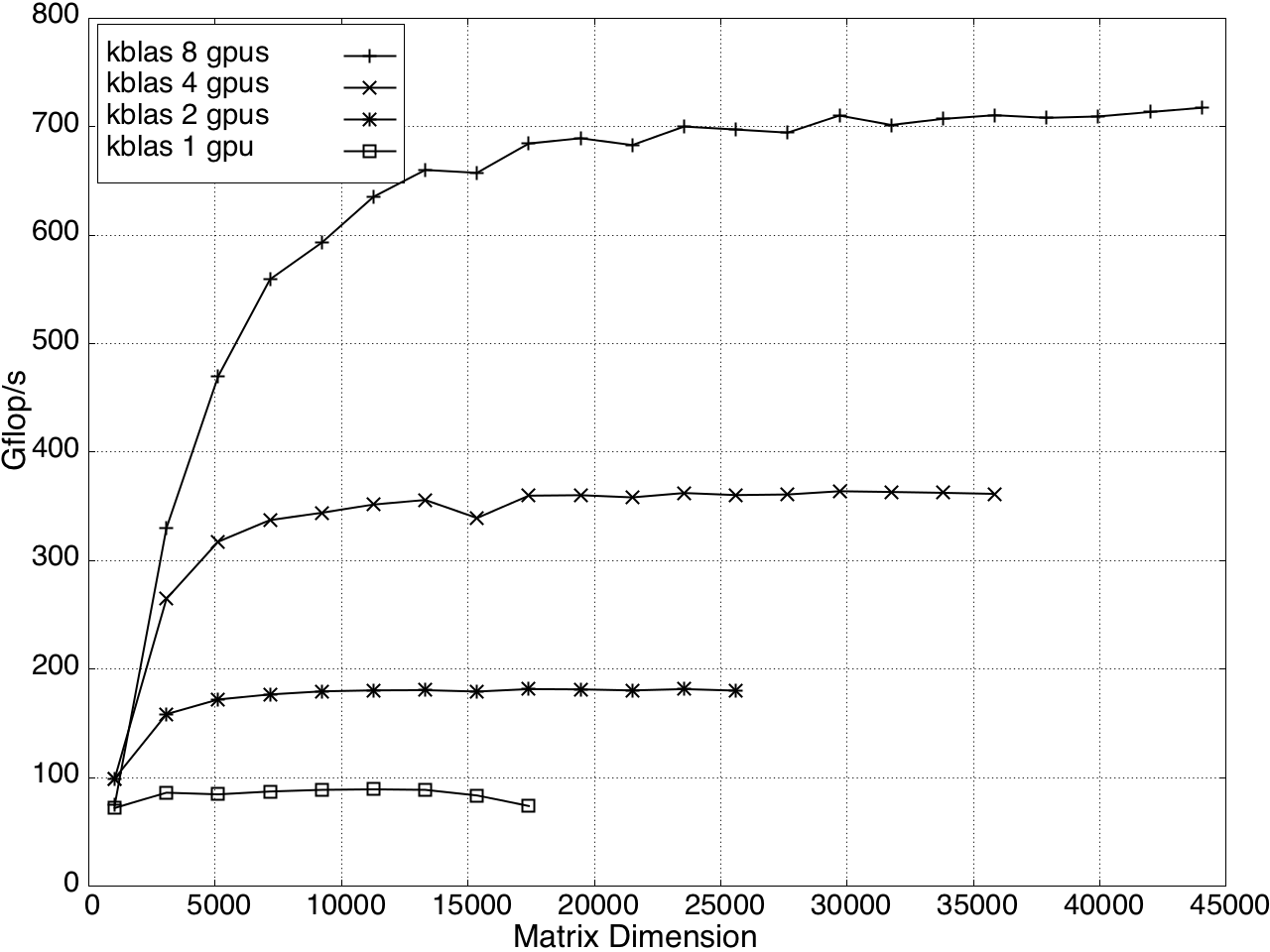
Figure 12: GEMV Performance on Multi-GPU, K20c with ECC off.
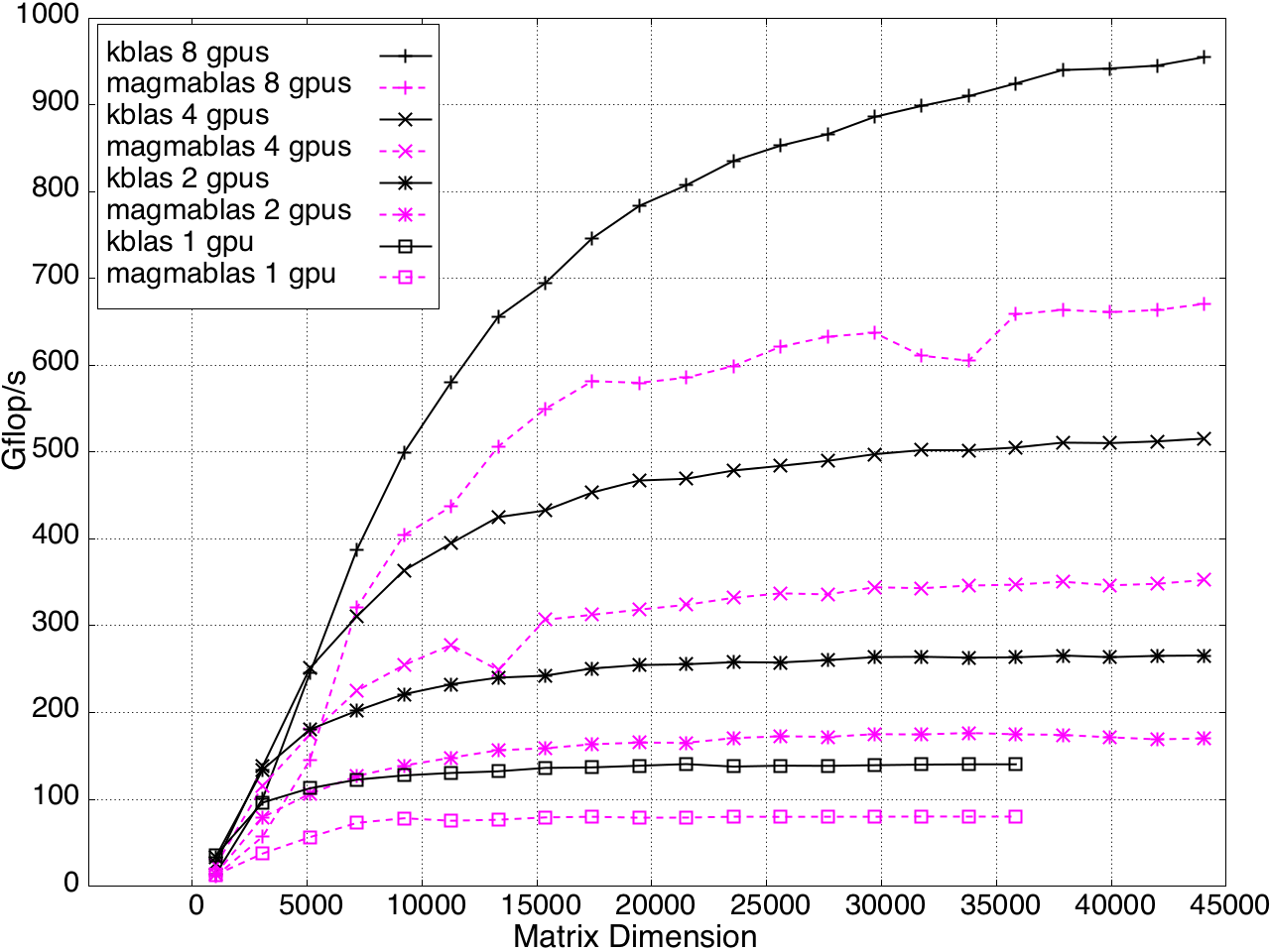
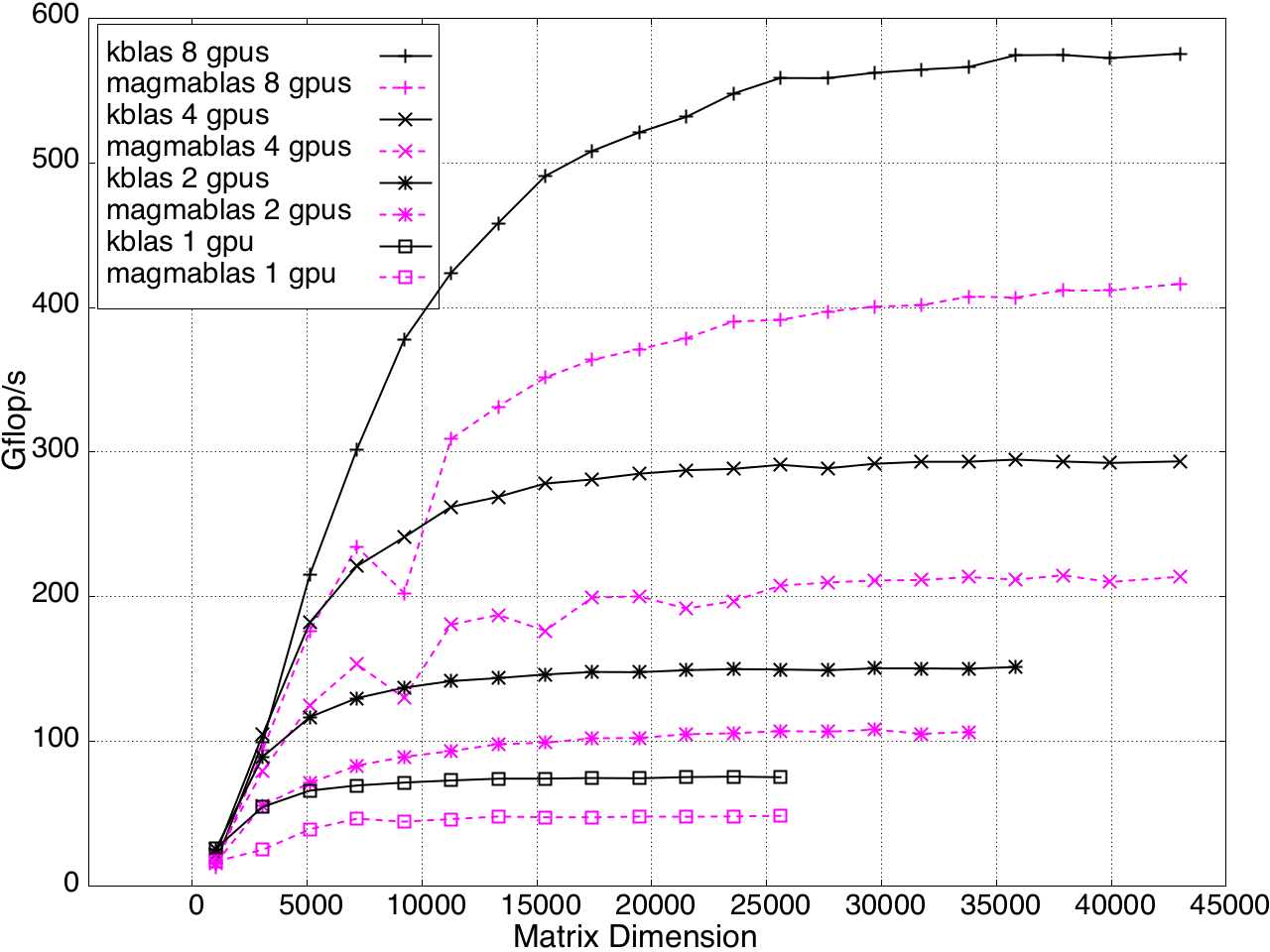
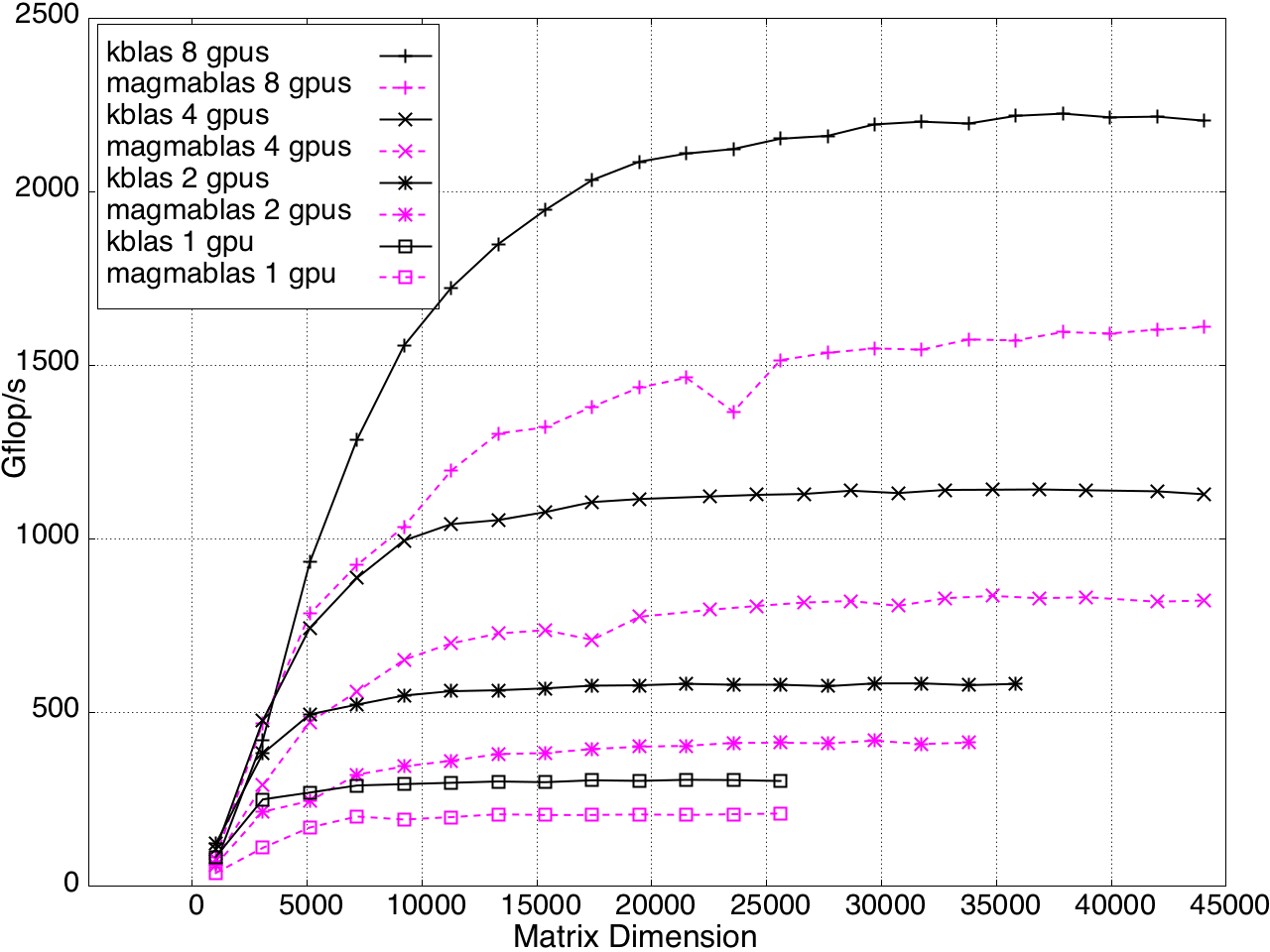
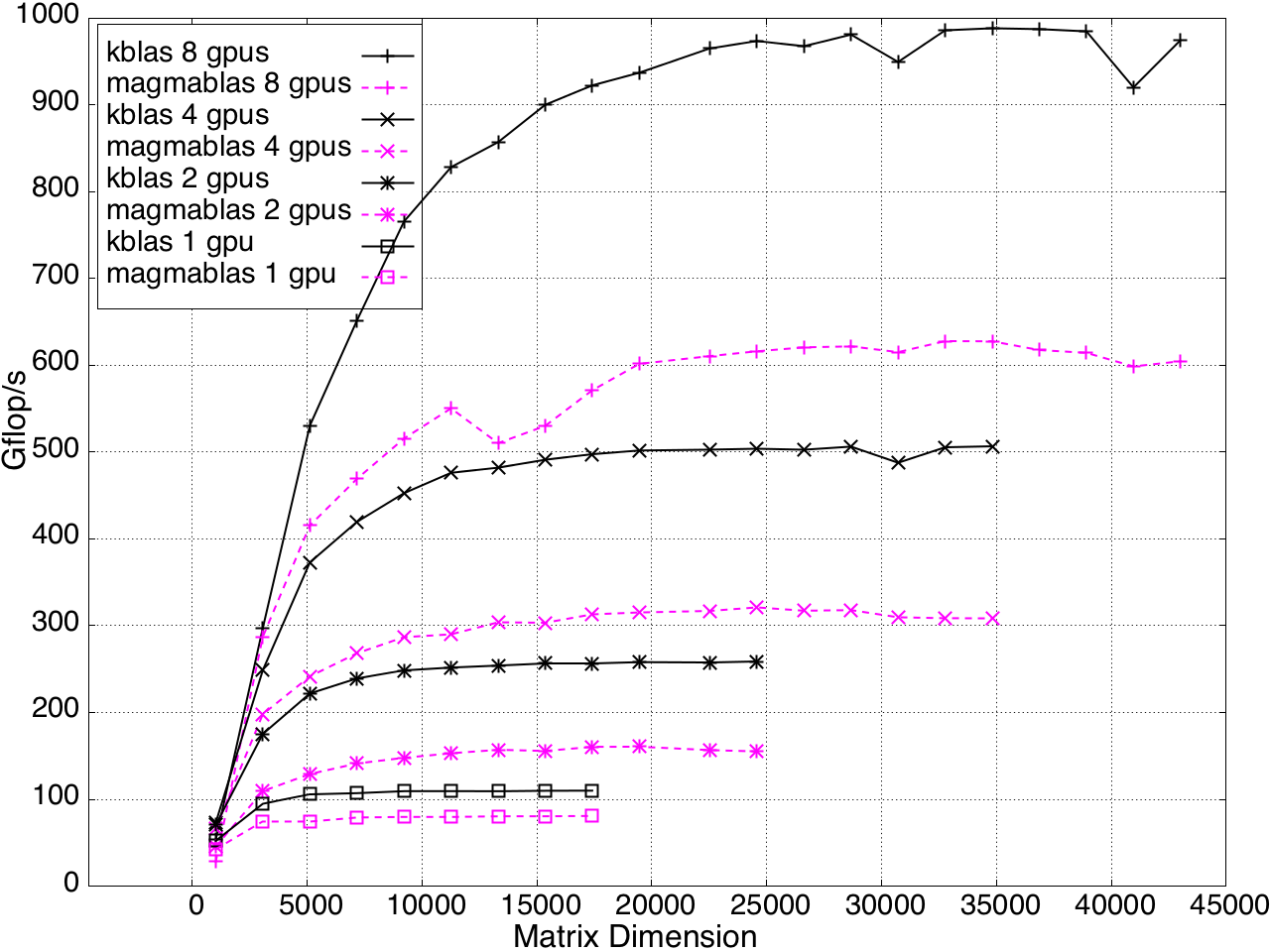
Figure 13: SYMV/HEMV Performance on Multi-GPU, K20c with ECC off.
The performance of KBLAS is tunable through parameters such as block size nb8, the number of thread columns nb9, and the number of TBs Xˉ0. Coarse tuning involves adjusting Xˉ1 and Xˉ2, while fine tuning adjusts Xˉ3 (Figure 14).
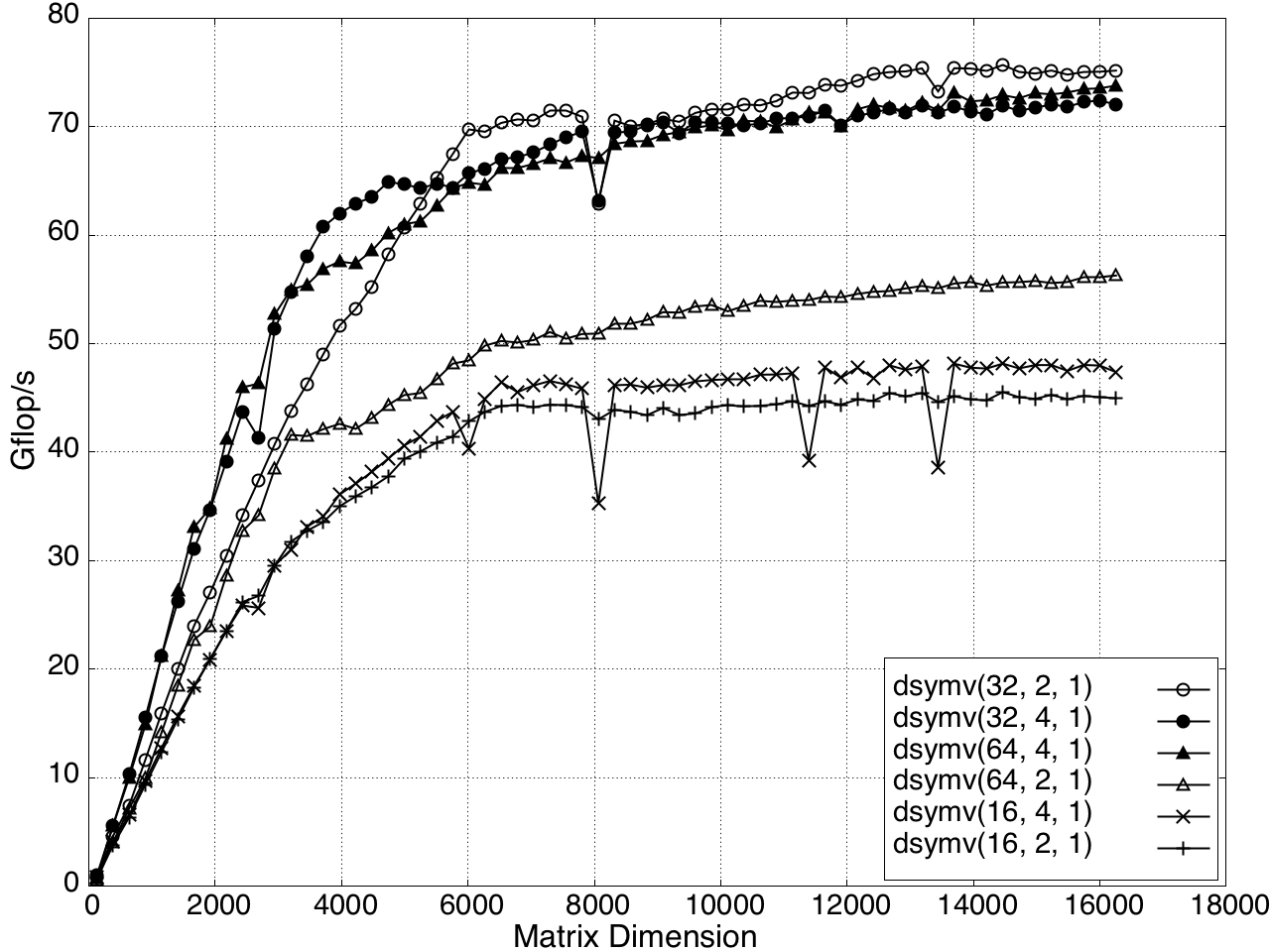
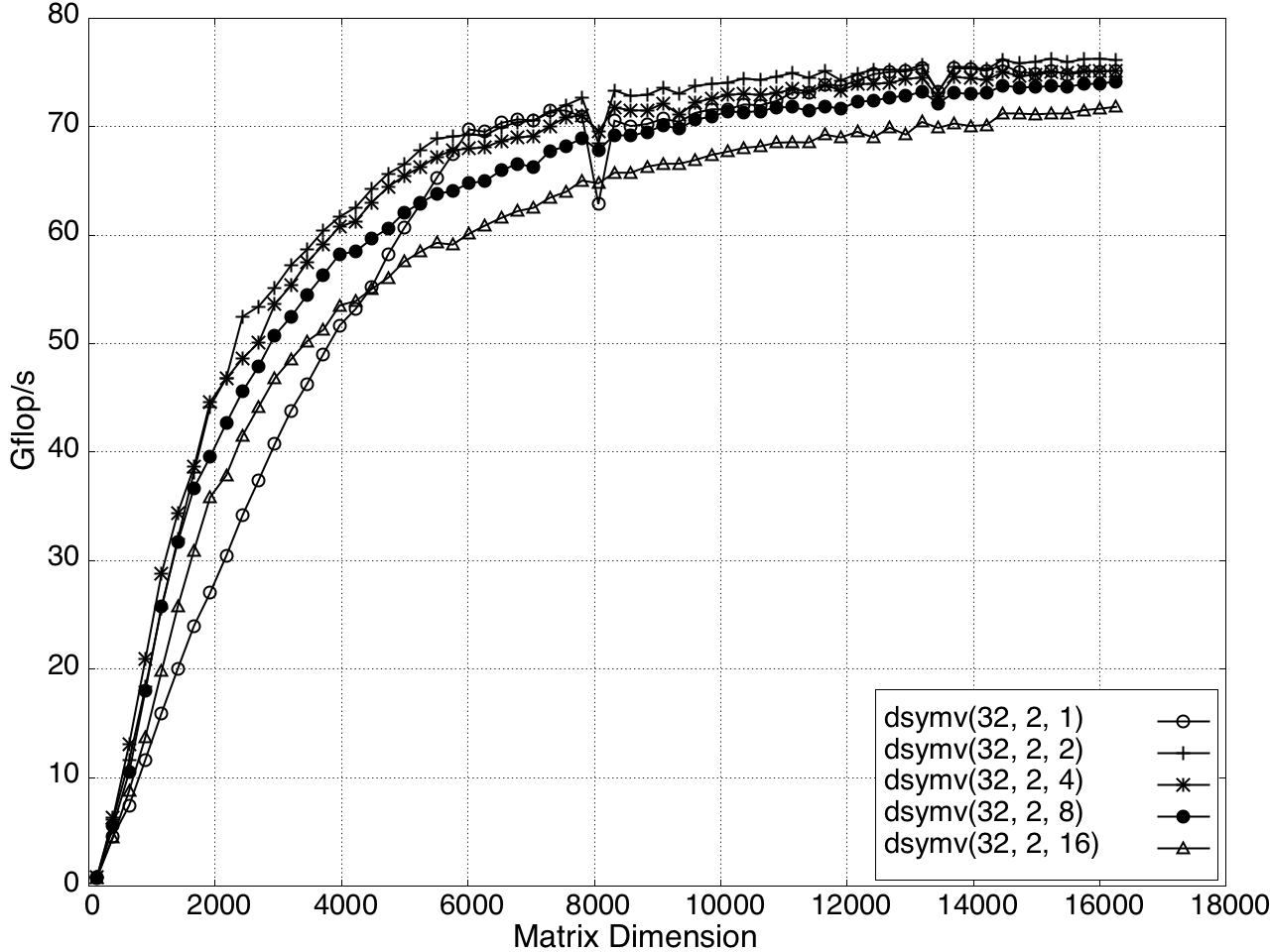
Figure 14: Performance Tuning of KBLAS-DSYMV Kernel on a K20c GPU.
The impact of the Xˉ4 value on the performance of the GEMV kernel is shown in Figure 15.
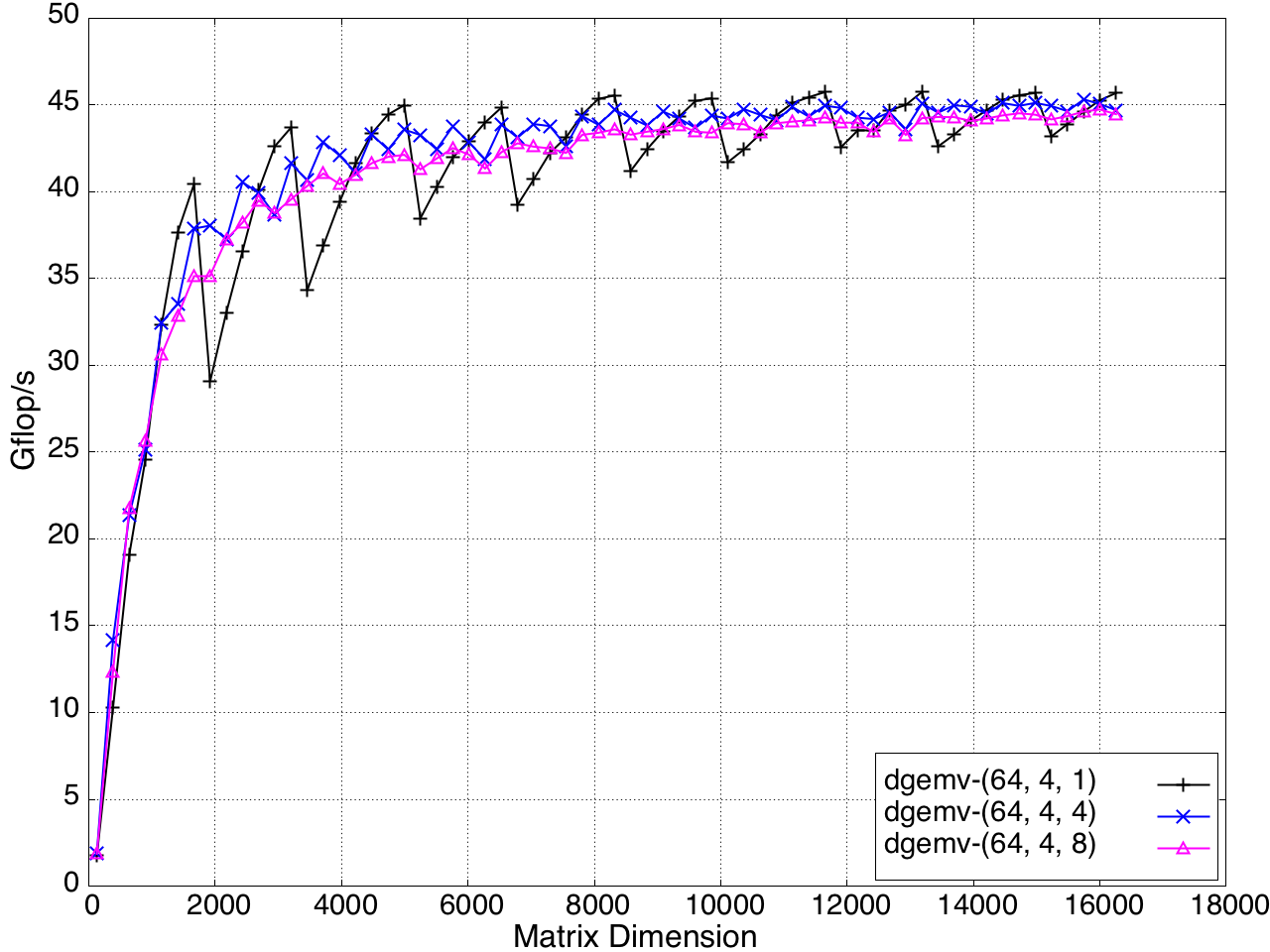
Figure 15: Impact of Xˉ5 on the Performance of the KBLAS-DGEMV Kernel.
KBLAS is integrated into MAGMA, improving the performance of GEBRD (Figure 16) and SYTRD/HETRD algorithms (Figures 19 and 20).
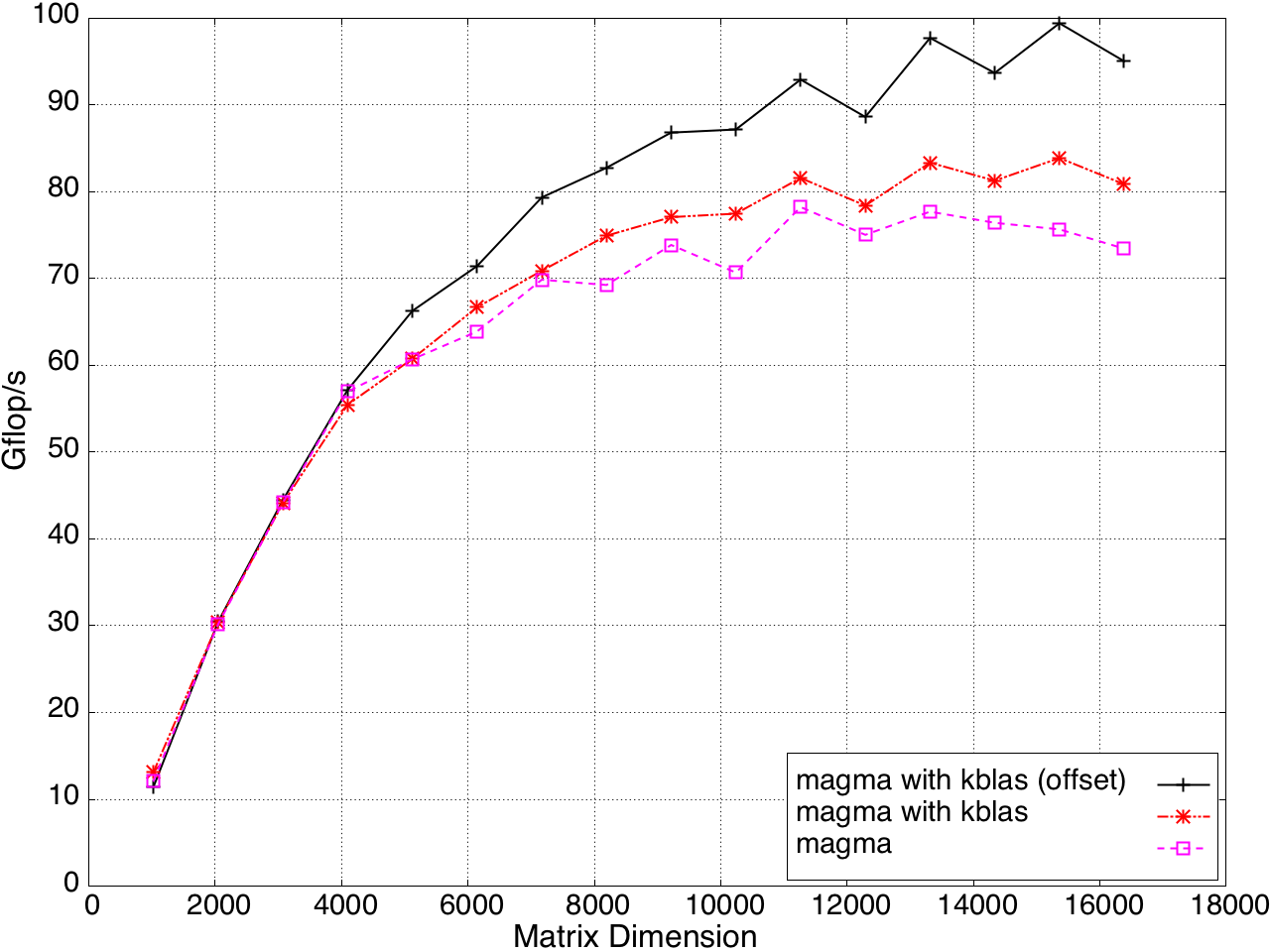
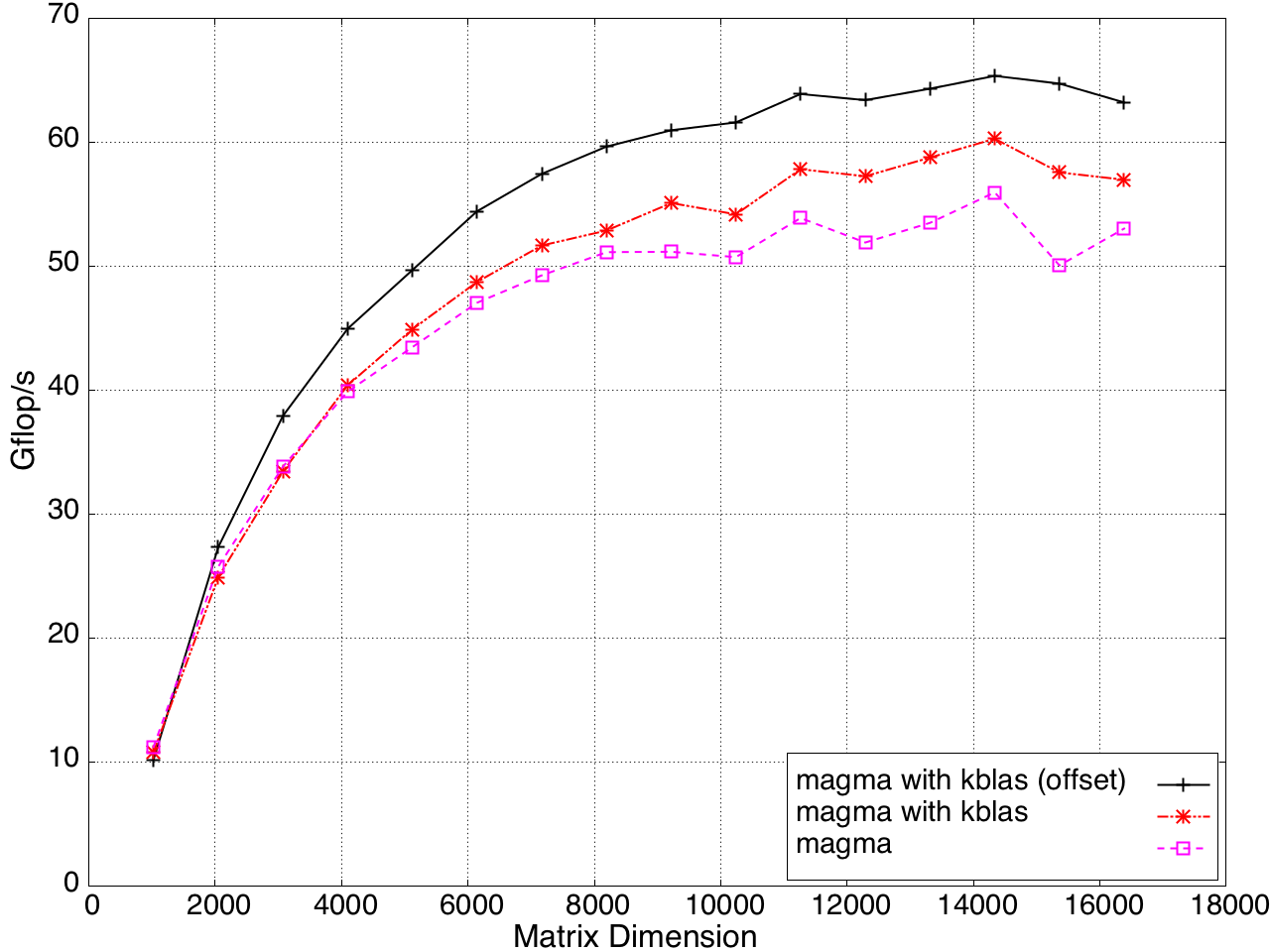
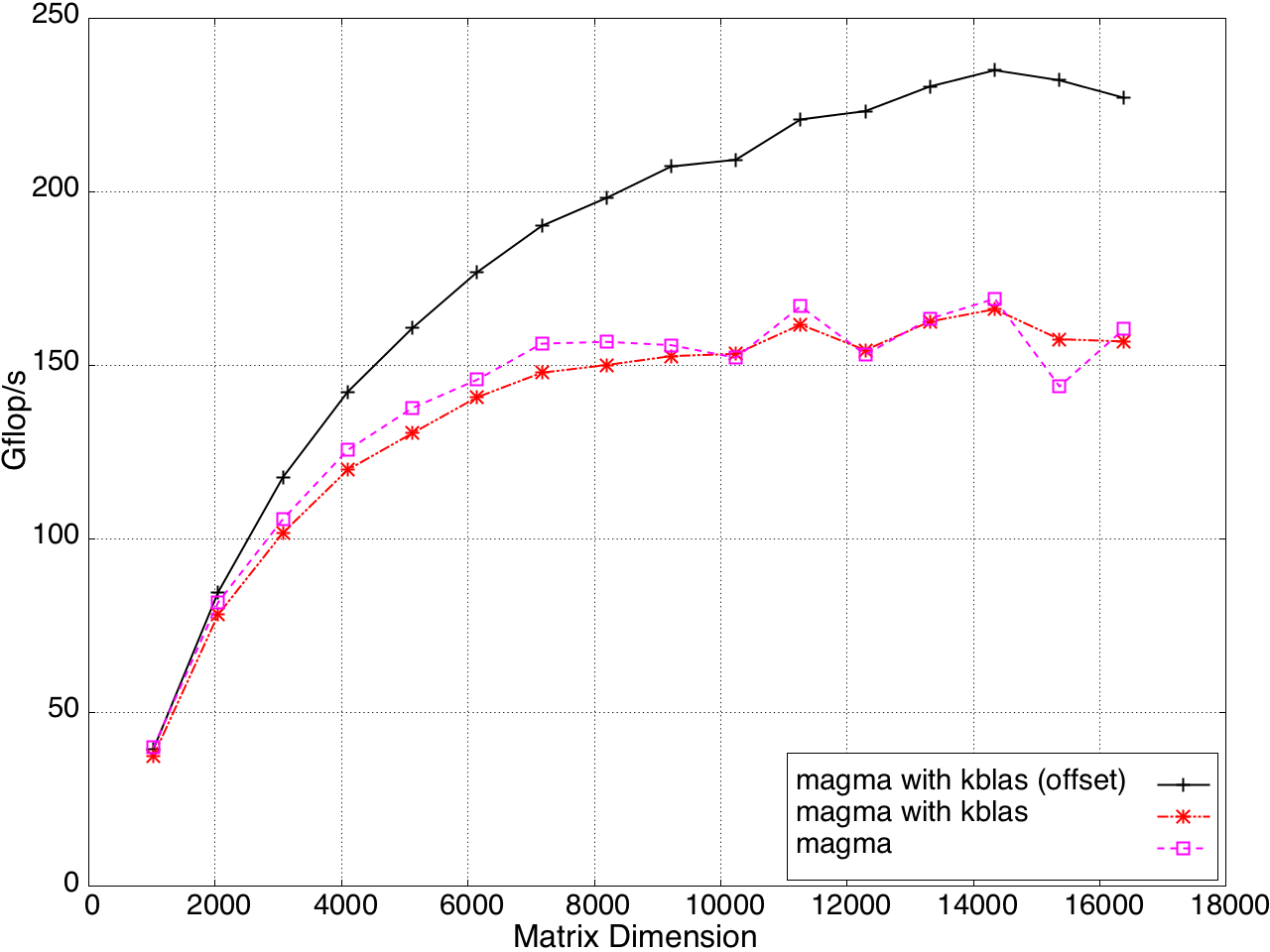
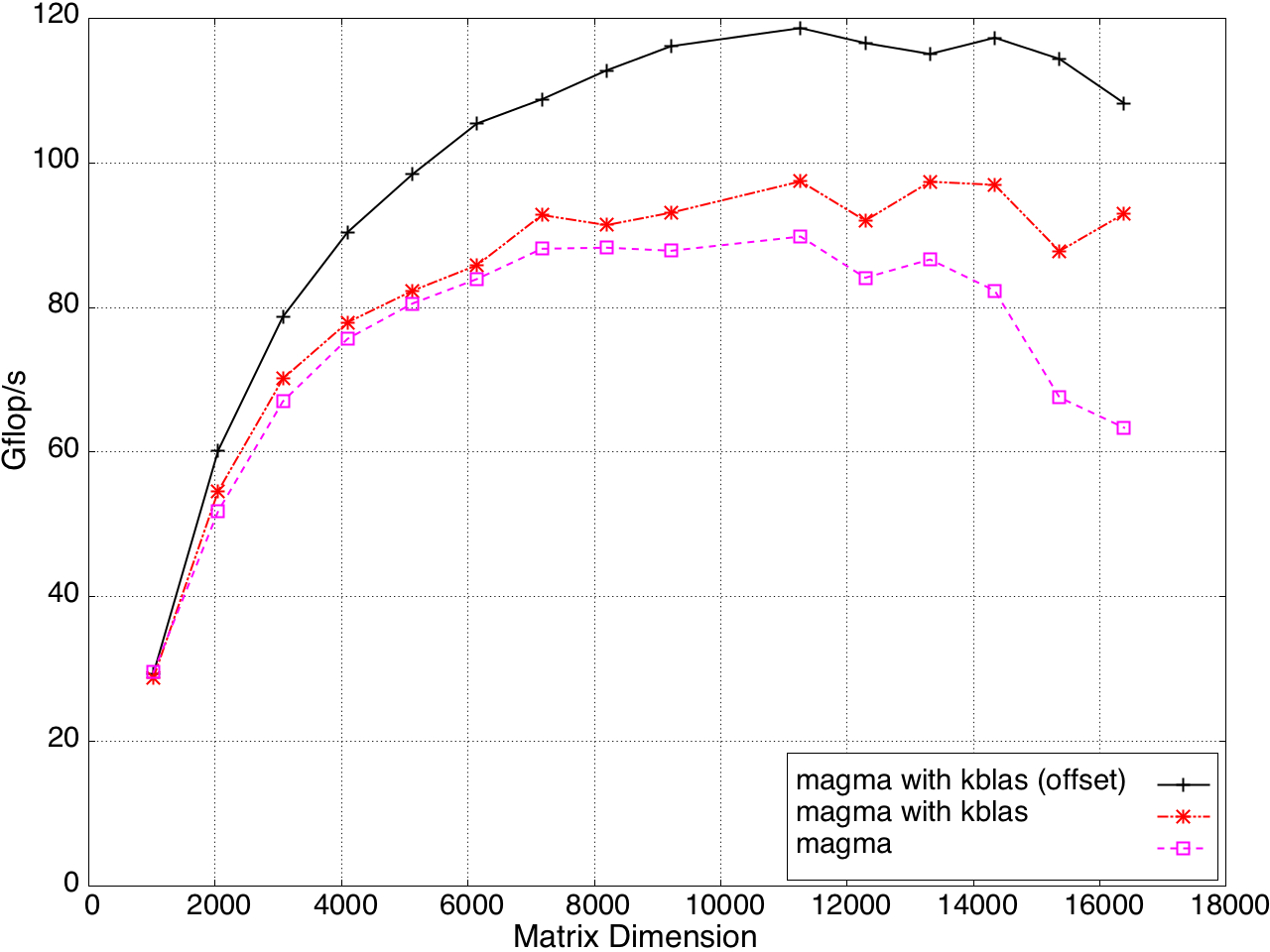
Figure 16: Bidiagonal Reduction Performance on a K20c GPU, ECC off.
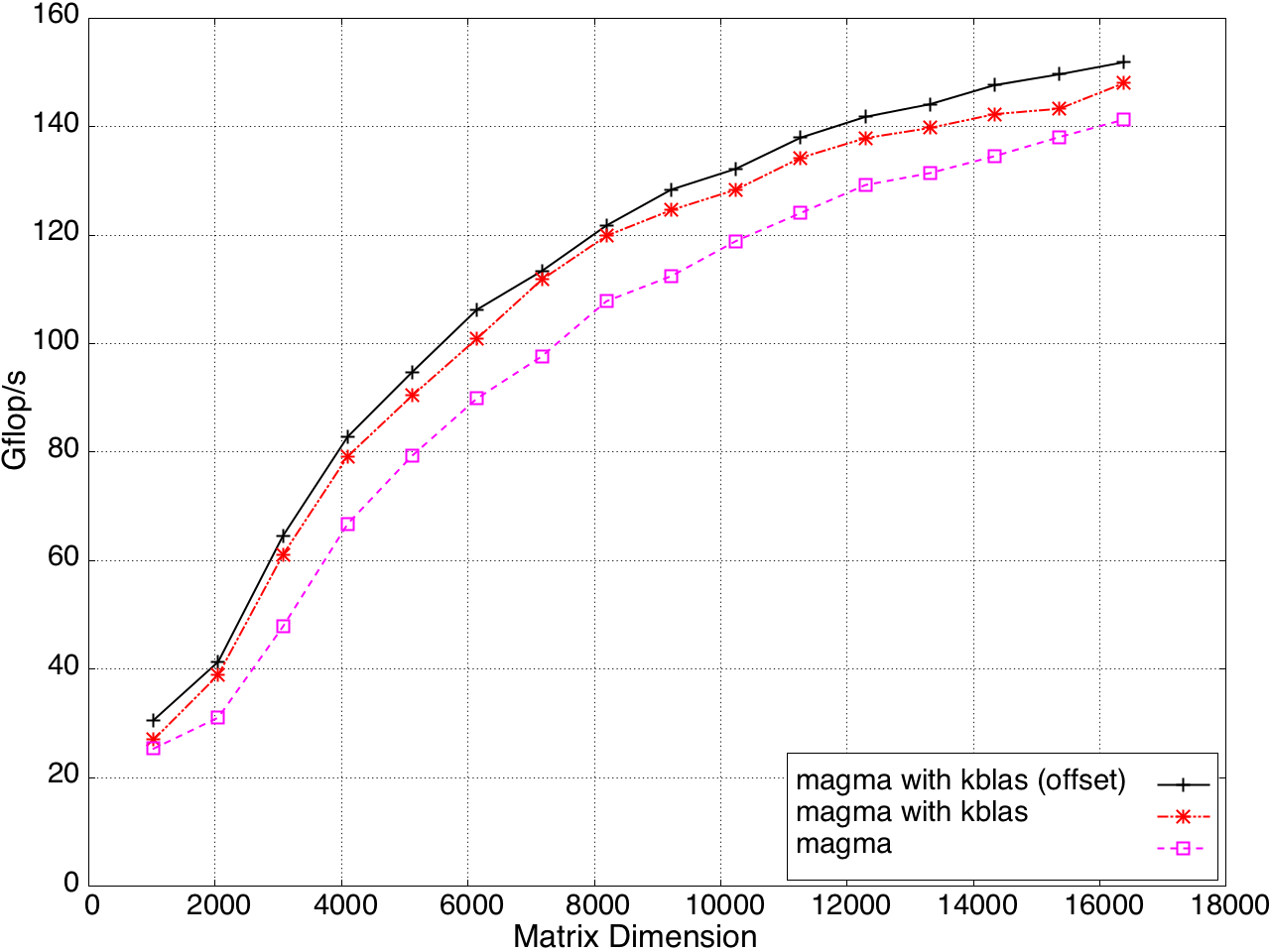
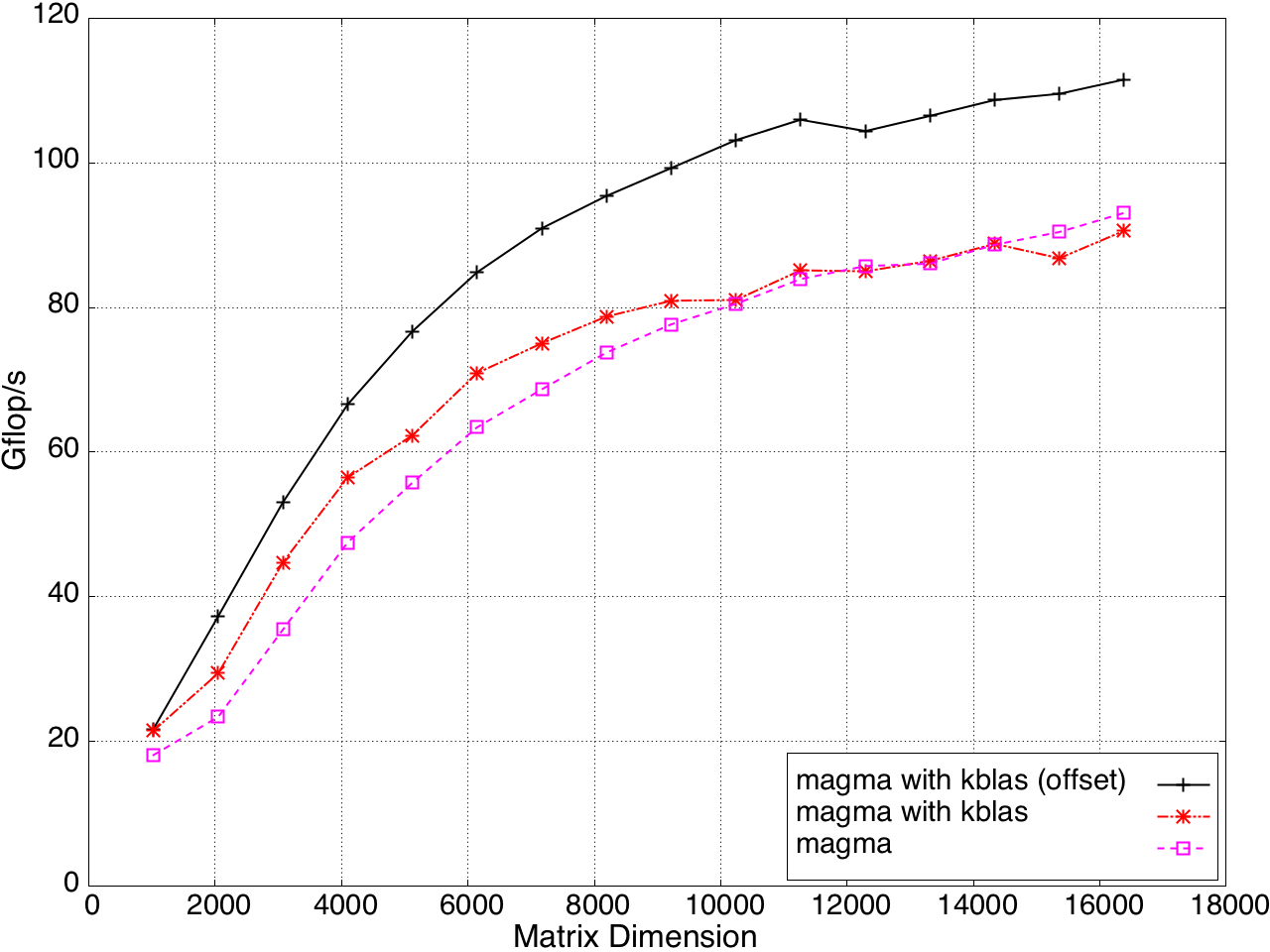
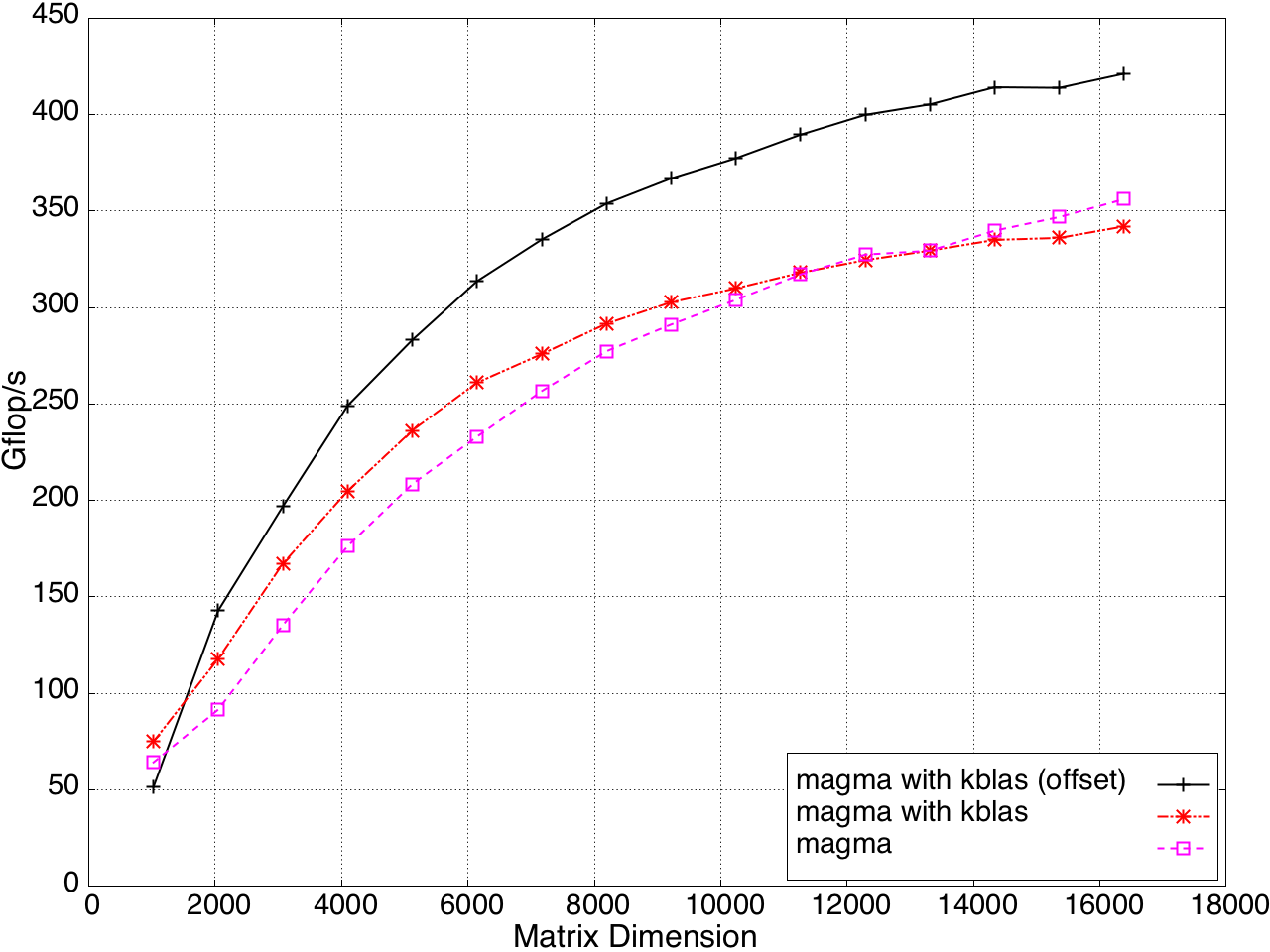
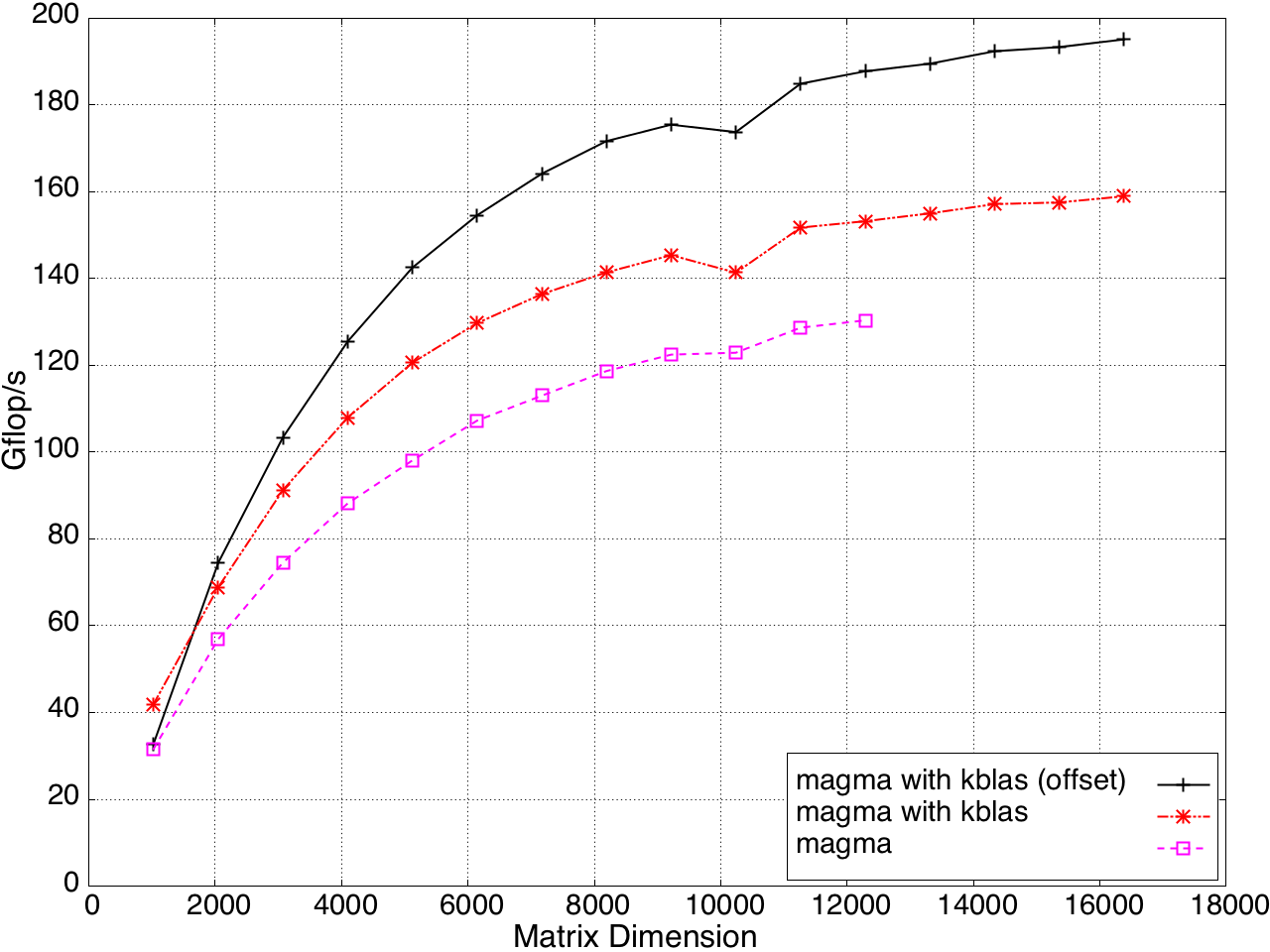
Figure 17: Tridiagonal Reduction Performance on a K20c GPU, ECC off.
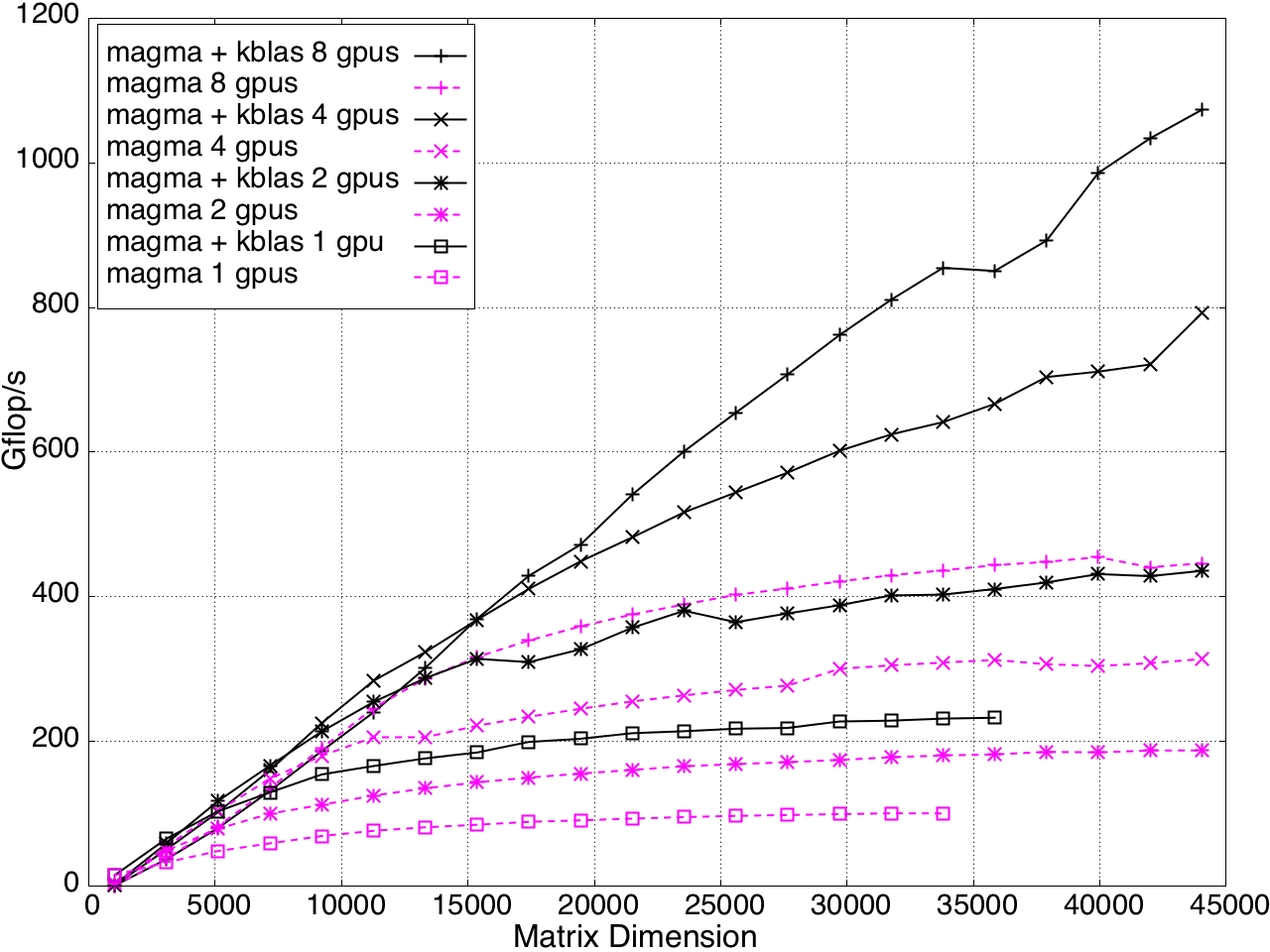
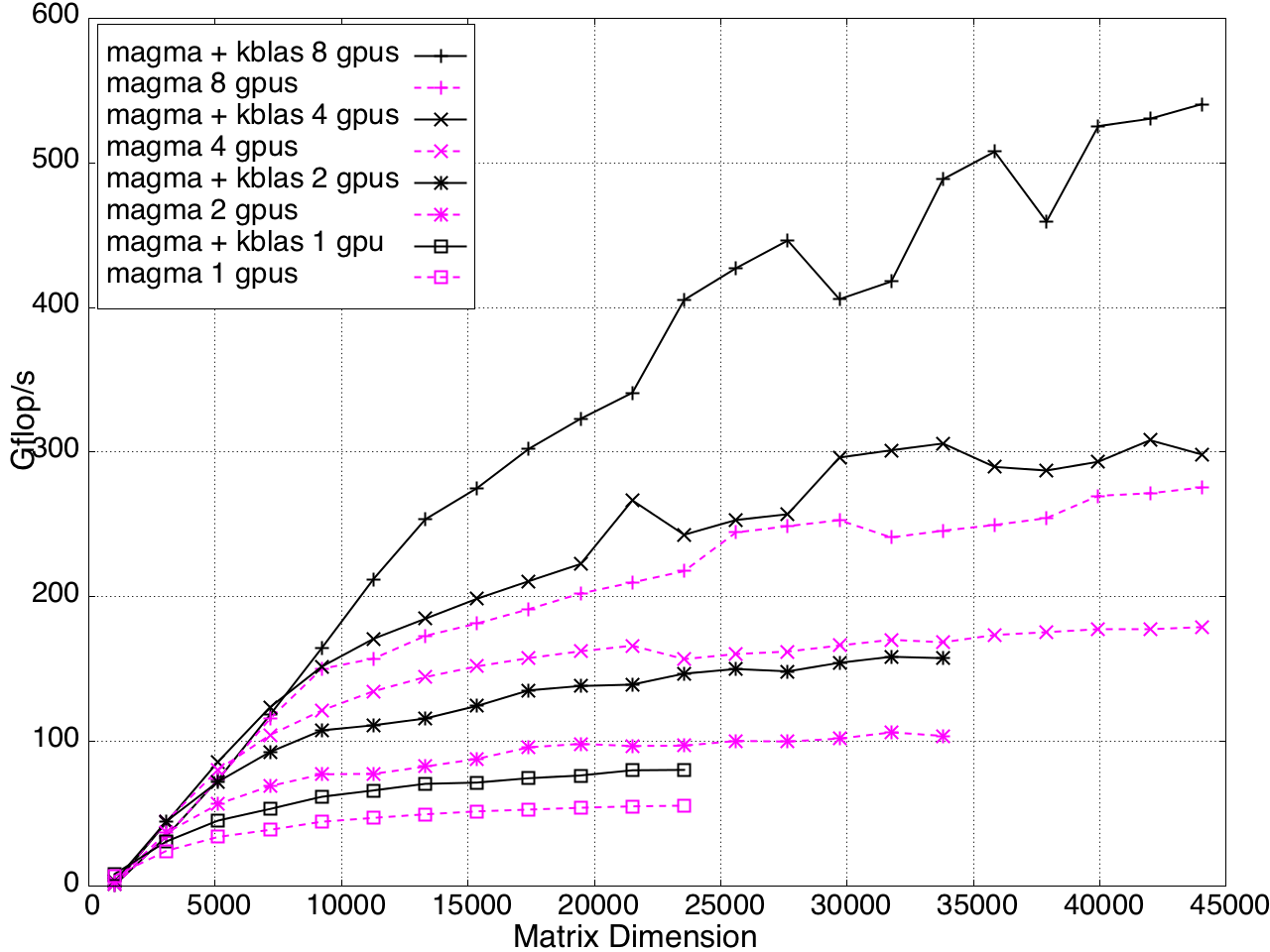
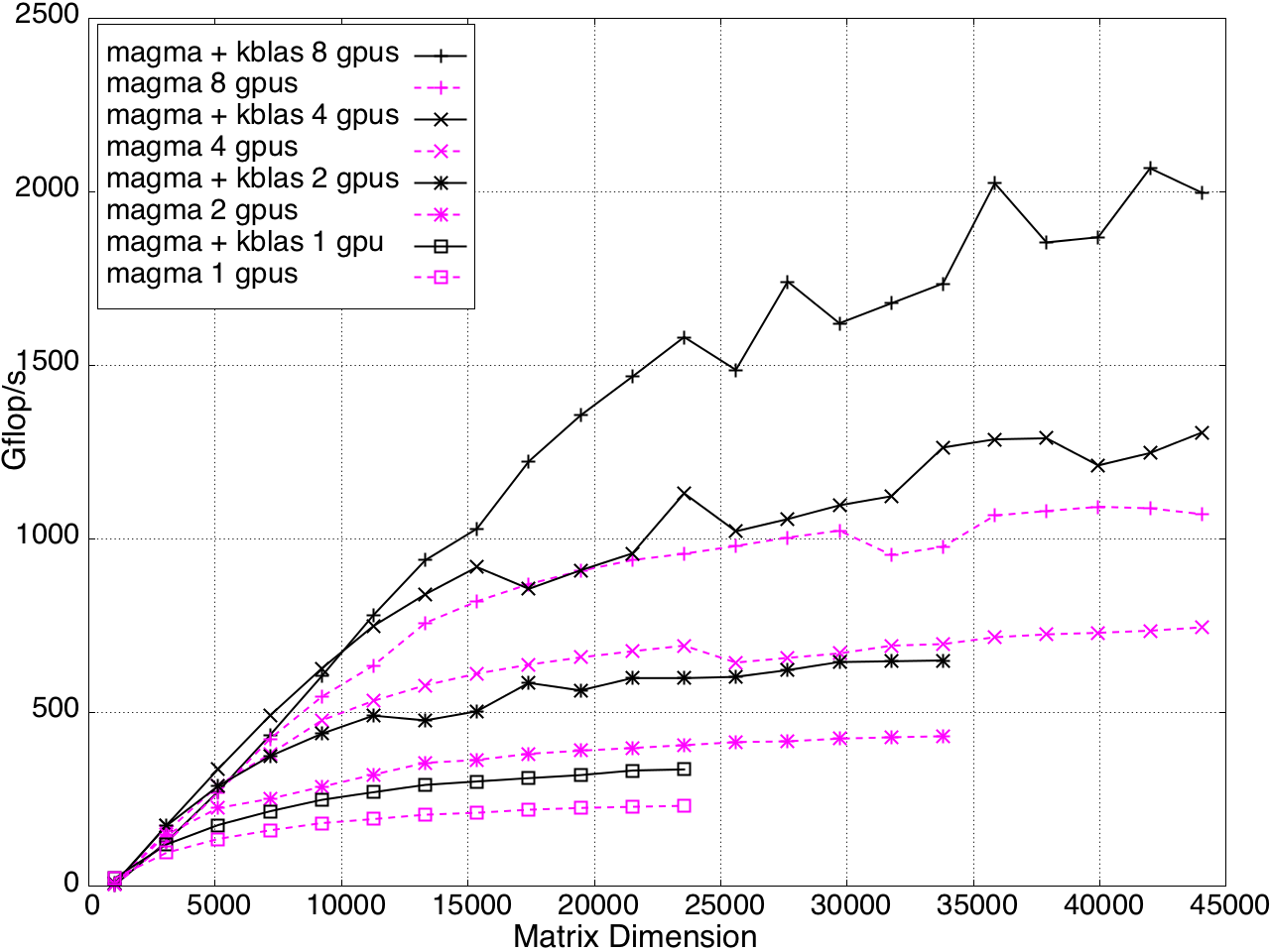
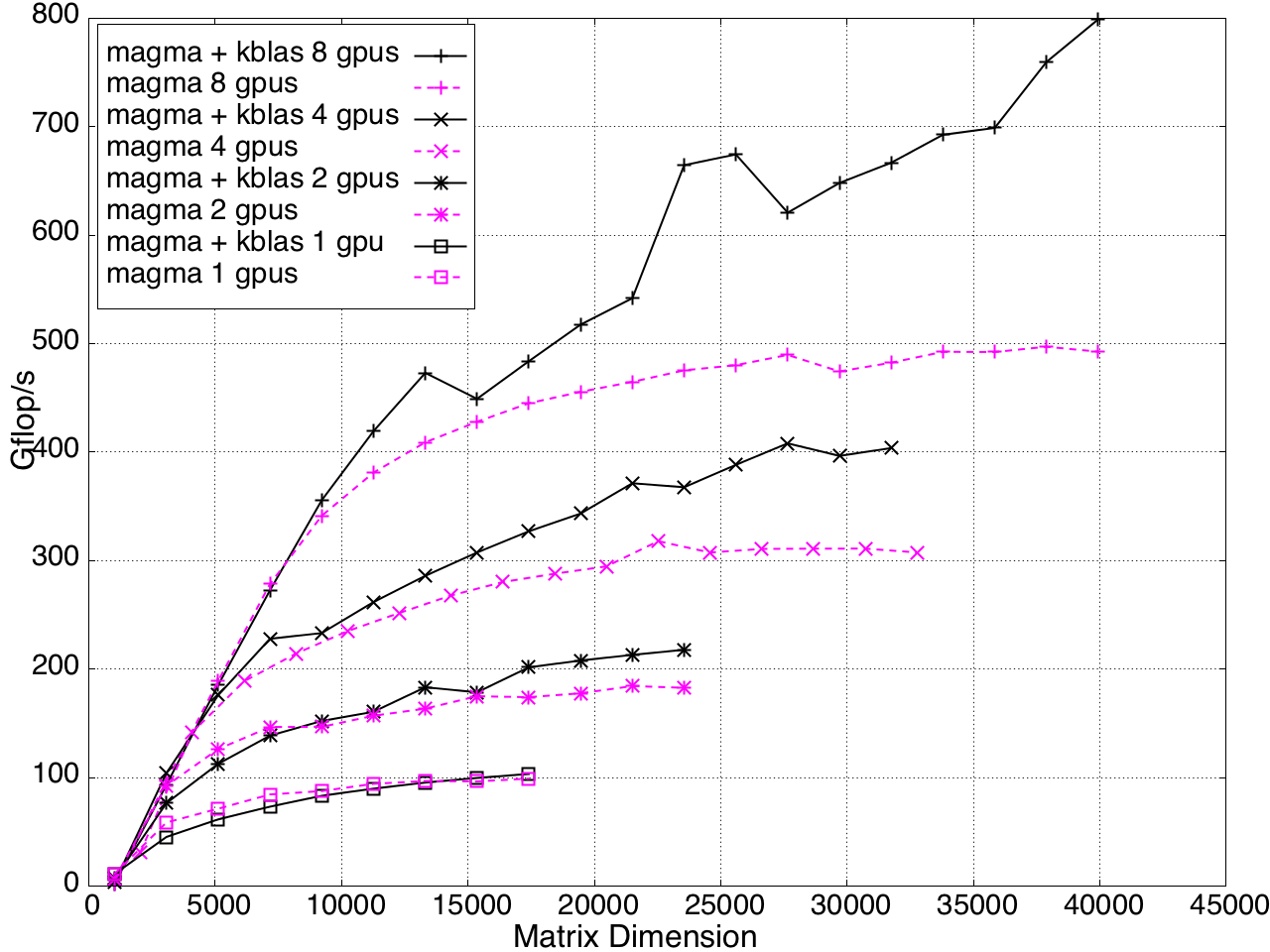
Figure 18: Tridiagonal Reduction Performance on Multi-GPUs, K20c GPU with ECC off.
Conclusion
KBLAS is an optimized library for dense matrix-vector multiplication on NVIDIA GPUs, outperforming state-of-the-art implementations and demonstrating performance portability across different GPU models through tunable parameters. Future work includes supporting more data layouts for multi-GPU routines, providing auto-tuning functionality, and applying KBLAS building blocks in Sparse Matrix Vector Multiplication (SpMV).

