- The paper presents UCF101, a benchmark dataset with over 13,320 video clips covering 101 human action classes.
- It employs a Bag of Words approach using Harris3D and HOG/HOF descriptors, achieving a baseline accuracy of 44.5% with 25-fold cross-validation.
- The dataset addresses real-world challenges such as dynamic backgrounds and camera motion, facilitating robust action recognition research.
Overview of the "UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild" (1212.0402)
The paper presents UCF101, the largest available dataset for human action recognition in videos at the time of its publication. This dataset addresses significant limitations in existing action recognition datasets by offering a comprehensive, diverse, and realistic collection of videos from YouTube. The dataset is pivotal for benchmarking action recognition models due to its substantial size and realistic, unconstrained conditions.
Dataset Composition and Characteristics
The UCF101 dataset comprises 101 human action classes with over 13,320 video clips, offering a wide range of actions nearly doubling the most extensive datasets available then (HMDB51 and UCF50). The authors categorize these actions into five primary types: Sports, Playing Musical Instruments, Human-Object Interaction, Body-Motion Only, and Human-Human Interaction. This classification presents more diversity and realism than previous datasets which often contained a limited number of staged or professionally filmed scenes, hence lacking the complexity of real-world dynamics.

Figure 1: Sample frames for 6 action classes of UCF101.
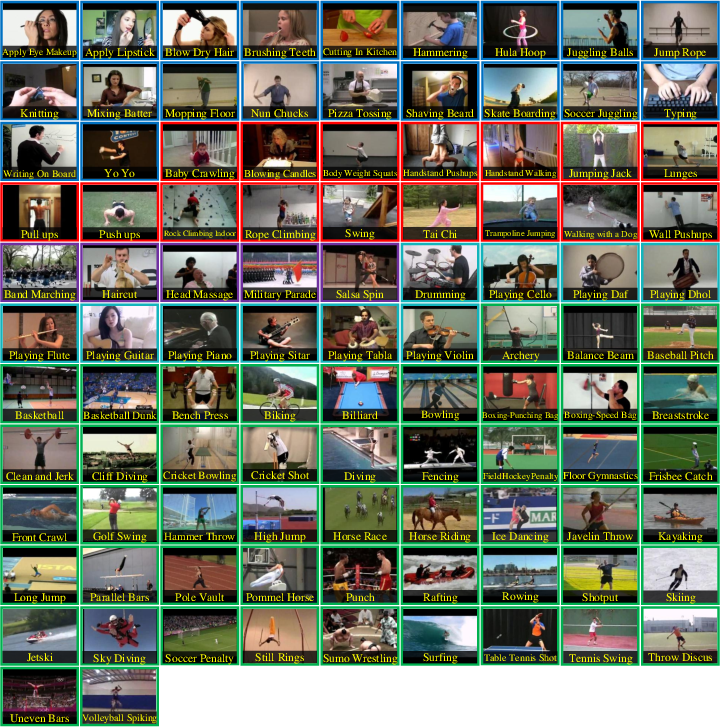
Figure 2: 101 actions included in UCF101 shown with one sample frame. The color of frame borders specifies to which action type they belong: Human-Object Interaction.
UCF101 stands out for its dynamic backgrounds, diverse camera motions, and varying video qualities. The dataset captures natural variations in lighting, occlusion, and significant camera movement, providing a robust platform for developing more generalized learning algorithms.
Experimental Framework
The authors performed baseline action recognition experiments using the popular Bag of Words (BoW) approach. In this study, Harris3D detector and HOG/HOF descriptors, which are part of the standard toolkit for spatiotemporal feature extraction, were employed. The descriptor space was quantized into a dictionary of 4000 visual words using k-means clustering on a sample of 100,000 space-time interest points to serve as input for a non-linear multiclass SVM employing a histogram intersection kernel. The study provides a foundation for benchmarking by recommending a 25-fold cross-validation experimental setup, ensuring uniformity across future evaluation on UCF101.
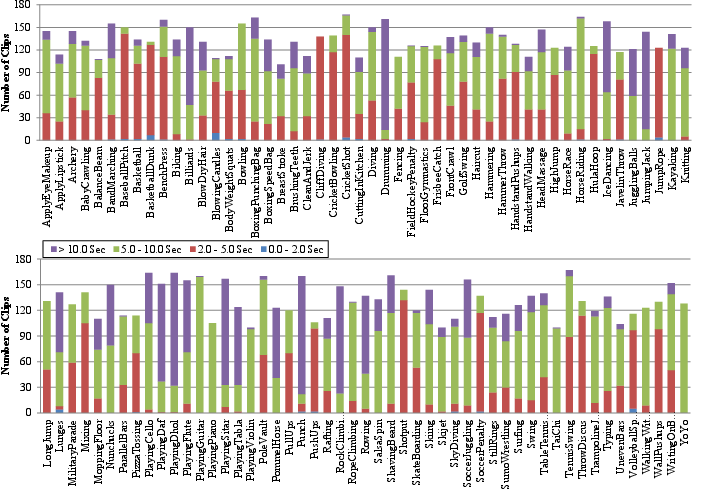
Figure 3: Number of clips per action class. The distribution of clip durations is illustrated by the colors.
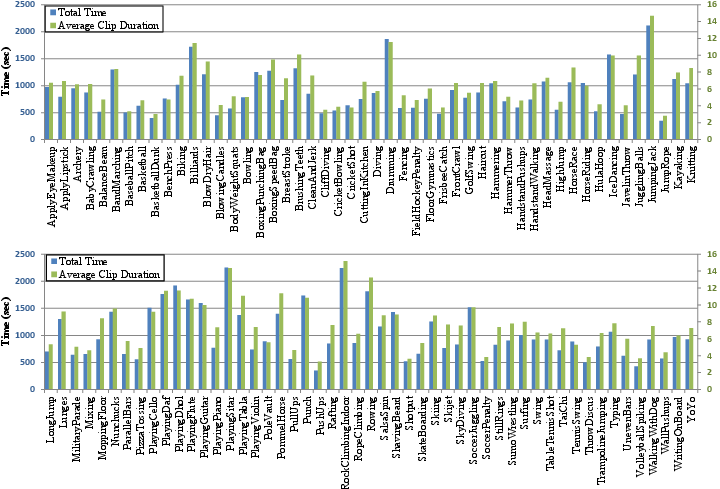
Figure 4: Total time of videos for each class is illustrated using the blue bars. The average length of the clips for each action is depicted in green.
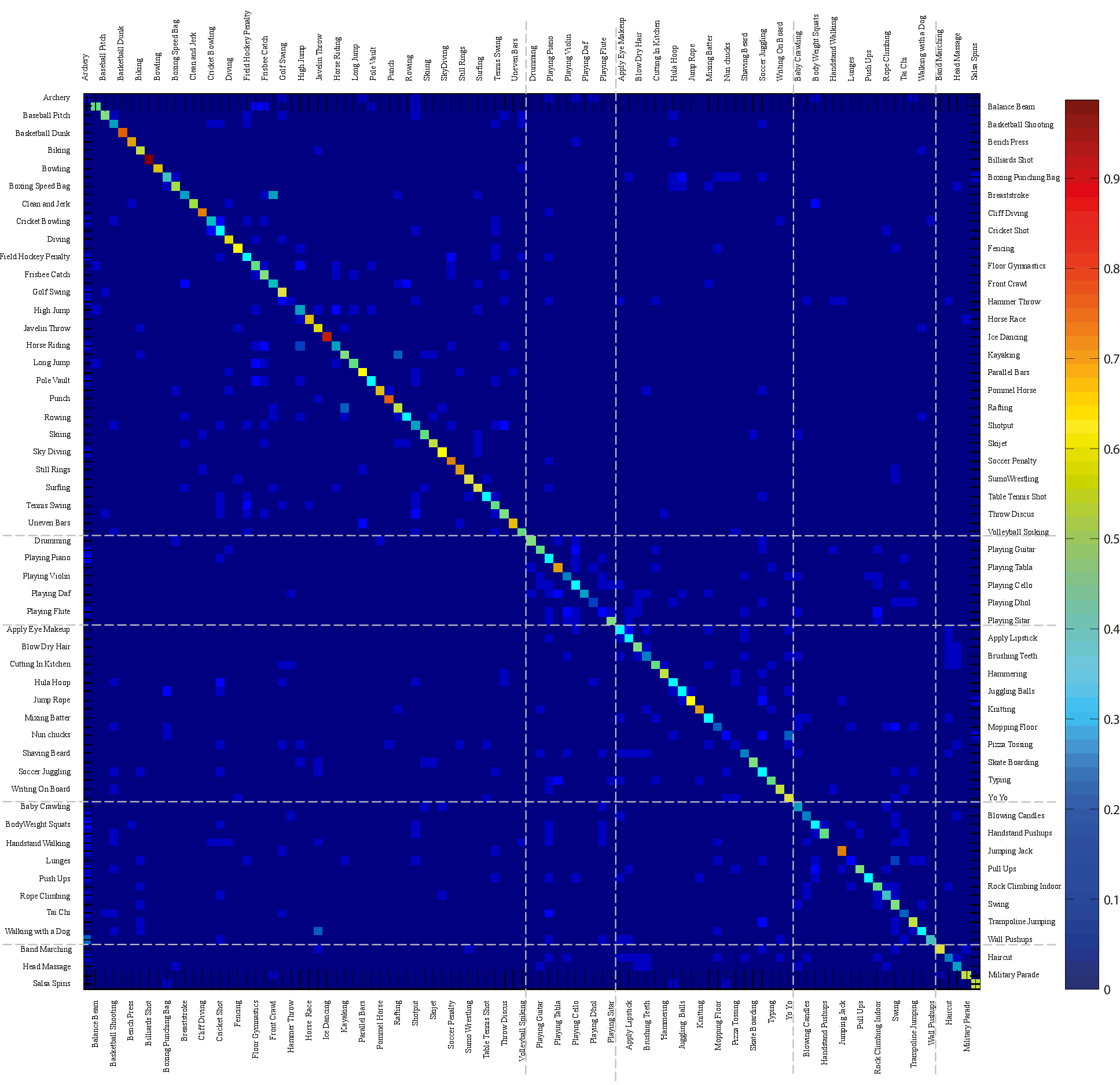
Figure 5: Confusion table of baseline action recognition results using bag of words approach on UCF101.
The performance of this 101-class SVM model with a histogram intersection kernel yielded an overall accuracy of 44.5%. Sports categories achieved the highest accuracy of 50.54% due to the distinctive nature of sports movements, which are easier to classify compared to other action types. The study highlights the challenges posed by the dataset's unconstrained nature, which includes variations in camera motion, background clutter, and occlusions, aligning closely with the challenges in real-world settings.
The paper evaluates UCF101 against previous action recognition datasets, detailing their number of actions, clips, and other characteristics. As shown, UCF101 surpasses existing datasets in both the number of action categories and the volume of clips, making it a valuable resource for advancing the state-of-the-art in action recognition.
Conclusion
In conclusion, "UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild" (1212.0402) establishes itself as a significant contribution to the action recognition domain. Offering a wide array of action classes and covering significant video footage, UCF101 provides an essential benchmark for researchers aiming to develop and optimize robust action recognition algorithms under real-world conditions. The baseline results underscore the challenges of real-world data, hinting at the necessity for advancement in action recognition methodologies. This dataset opens pathways for future work to address complexities like camera motion, dynamic backgrounds, and intra-class variability.